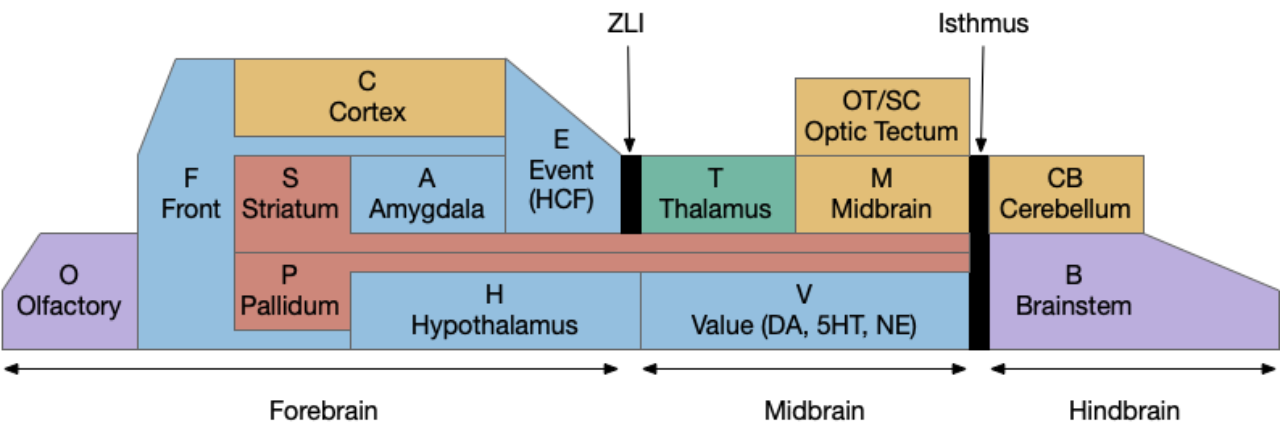
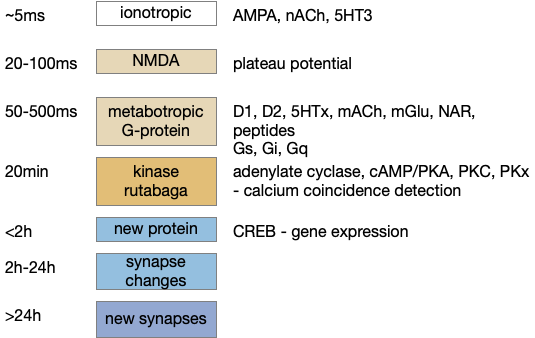
[Sossin 2008] discusses the problem of timescales of memory at the neuron level, where the human “short term” and “long term” notions don’t map cleanly to neurons and synapses. Instead, tagging by the biochemical process is more useful.
Neuronal biochemical memory processes and associated timescale
One dividing line between short term memory and long term memory is new protein synthesis. In this model, short term uses materials and proteins already available to the cell, and long term uses new proteins or new structural changes. In the diagram above, the blue items are new proteins.
Short term memory also covers very short, including the 20-500ms range of slower neurotransmitters. While that timeframe might not seem like memory, compared to the 5ms of fast neurotransmitters, it is storing a memory of the faster responses. As a comparison to electrical circuits, the 20-500ms range is like an electrical latch, which is a memory circuit for very short time periods, typically one clock cycle. The 20-500ms range in neural circuits covers both the common gamma and theta clock cycles in the vertebrate brain, and may serve a functional role similar to electronic latches.
Essay 16 extends the odor seeking (chemotaxis) of essay 15 by adding a single memory item. The memory caches a failed odor search, avoiding the cost of searching for false odors. The neuroscience source is the fruit fly Drosophila. The simulation is still based on a Braitenberg slug with distinct circuits for chemotaxis and for obstacle avoidance.
The fruit fly mushroom body (MB) is the learning center. MB is a modulating system: if it’s knocked out, the fruit fly behaves normally, although with only intrinsic, unlearned behavior. Essay 16 focuses on a single MBON short term memory (STM) output neuron, which may specifically be the γ2 neuron.
For simplicity and focus, essay 16 isn’t implementing the KC yet. Instead, the γ2 MBON receives its input directly from a small number of odor projection neurons (PN) that was implemented in essay 15. Essentially, the input is a small set of primitive odors, where the full KC is a massive combinatorial odor spectrum.
Candidate odors from evolution
To motivate why evolution might develop learning, consider the food-seeking slug from essay 15. Since the food odor in essay 15 perfectly predicted food, there was no reason to learn anything about food. The simulation’s “evolution” has perfectly solved the artificially perfect world, selecting exactly those odors needed to find food.
Choosing the right set of candidate odors is a dilemma for evolution. Too many candidates means wasted search time. Too few candidates avoids wasted time, but misses out on opportunities, which may be a smaller problem than too many candidates because the animal can fall back to random, brownian-motion search. This beast against including semi-predictive odors might mean that early Precambrian evolution might only favor the highest predictors and skip semi-productive odors.
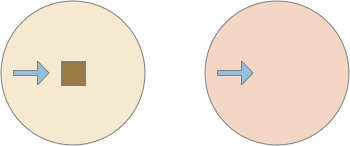
Candidate odor surrounded by distractors
The preceding image represents odors potentially available to the slug from an evolutionary design perspective. If the beige color is the only candidate for food, the slug will ignore the blue-ish colors because it never senses the odor. There’s no need for a circuit or behavior to distinguish the two. For the animal, those odors don’t exist.
Food odors don’t perfectly predict food, either because of lingering odors or simply candidate odors that aren’t always from nutritious food. For example, the fruit fly can taste sweet and it can also sense nutrition from a rest in blood sugar. That distinction between sweet and nutritious is reflected in the mushroom body with specific neurons for each [Owald et al. 2015].
Classical association
For this essay, let’s explore what could be the most trivial memory, in the context of the fruit fly MB. The MB output has only 24 neurons in 15 distinct compartments per hemisphere. Each compartment appears to have specialized roles, such as short term memory (STM) vs long term memory (LTM) [Bouzaiane et al. 2015], and water seeking compared to sugar seeking [Owald et al. 2015].
Although learning studies typically use classical association (Pavlovian) terminology, where a conditioned stimulus (CS) like the food odor becomes associated with an unconditioned stimulus (US) like consuming food, I don’t think that framing is useful for the odor-seeking behavior of the simulated slug.
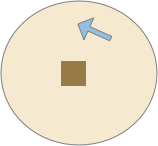
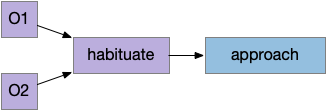
Naive animal missing food before classical training
In the diagram above, which follows the classical model, the animal (arrow) missing the food (brown square) despite being in the candidate odor’s plume because it hasn’t learned the associate the odor (CS) with the food (US). It only learns the association if it finds the food through brownian random search. Even then, if it randomly hits another food source with a different odor, it will forget the first, limiting the gain from this learning.
Even the non-learning algorithm of essay 14 performs better, because naive searching of all candidate odors is relatively successful, even if slightly time inefficient. Behaviorally, the difference is between default-approach or default-ignore. Default-approach needs to learn to ignore and default-ignore needs to learn to approach.
Learning to ignore
Learning to ignore is an alternative to the classical associative way of looking at the problem. It’s not an argument against classical conditioning in total, but it is a different perspective that highlights different features of the problem.
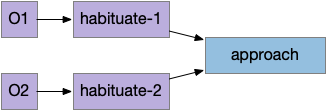
Successful approach to food and failure
The diagram above shows a successful approach to food and an unsuccessful approach. Both candidate odors potentially signal food because evolution ignores useless odors, but in this neighborhood the reddish odor is a non-food signal. As in essay 14, habituation will rescue the animal from perseveration, spending infinite time exploring a useless odor, but once an odor is found useless, ignoring it from the start would improve search efficiency.
Since odors in a neighborhood are likely similar, the animal is likely to encounter the useless odor soon. So, remembering a single item, like a single item cache, will improve the search by avoiding cost, until the animal reaches an area that does have nutritious food. The single-item cache lets the animal ignore patches of non-predictive odors.
Single item cache (short term memory)
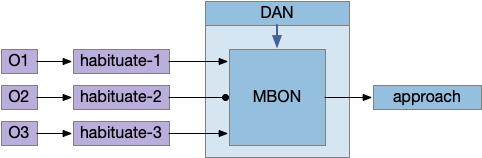
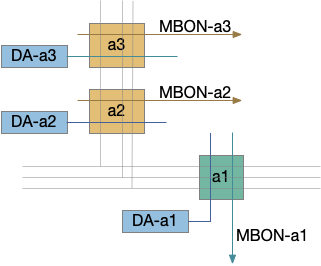
A single mushroom body output neuron (MBON) and its associated dopamine neuron (DAN) can implement a single item cache by changing the weights of the KC to MBON synapses with long-term depression (LTD). Following the previous discussion, since it’s more efficient to remember the last failure than the last success, the learning is LTD at the synapse between the odor and the MBON. In fruit flies, short term memory (STM) is on the order of 2h. (For a fuller discussion between “short” and “long” term see [Sossin 2008].)
Reduced MB circuit for negative learning
In the above diagram, the O2 synapse with a ball represents the LTD cache item. If the animal senses odors for either O1 or O3, it approaches the odor. If it senses O2, it ignores the odor because of the LTD at the synapse. (The colors follow the mnemonic model. Purple represents primary sensor/odor, and blue represents apical/limbic/odor and motivation areas.)
The DAN needs to implement a failure signal to implement LTD, which is actually relatively complicated. Unlike success, which has an obvious direct stimulus when finding food, failure is ambiguous. How long the animal should persist before giving up is a difficult problem, and at very least requires a timer even for the simplest strategy. Because habituation already implements a timeout, an easy solution is to copy the circuit or possibly use its output. So, if the animal exists the odor plume because of habituation, the DAN might signal failure.
Another possibly strategy is for the DAN to continuously degrade the active signal as in habituation, and only rescue the synapse when discovering food. Results from [Berry et al. 2018] show the needed degrading over time (ramping LTD) in their study of MBON-γ2, although that study didn’t explore the rescuing of approach by finding food that we seed.
So, the second strategy might require a second, opposing neuron, which I’ll probably explore later. For this essay, the DAN will produce a failure signal on timeout and a success signal on finding food, something like a reward prediction error signal from reinforcement learning [Sutton and Barto 2018], but without using a reinforcement learning architecture.
Mammalian correlates
In mammals, the KC/MBON synapse with DAN modulation circuit functionally resembles the hippocampus CA3 to CA1 synapse (E.hc, E.ca1, E.ca3) with locus coerulus (V.lc). In mammals, V.lc is known as the primary source of noradrenaline, associated with surprise and orientation, but it also contains dopamine neurons, and strongly innervates the hippocampus.
[Aston-Jones and Cohen 2005] discuss the locus coeruleus involvement in decision-making, specifically in explore vs exploit decision. If time passes and exploitation continues to fail by not finding food, V.lc signaling encourages moving on and exploring different options, a behavior similar to ours.
The E.ca3 to E.ca1 connection (and E.ec, entorhinal cortex) is believed to detect novelty, and V.lc is active during exploration, Like the fruit fly MBON, the hippocampus uses LTD to learn a new place, using V.lc signal [Lemon et al. 2012] like the DAN.
In contrast with my simulated slug, since the E.hc novelty output doesn’t directly drive food approach, because the mammalian brain is far more complex and abstract, the comparison isn’t exact, but it is an interesting similarity.
Simulation: shared habituation
In essay 15, the simulated slug approached an intrinsically attractive odor to find food, but needed a habituation circuit to avoid perseveration. The fruit fly LN1 neurons between the ~50 main olfactory sensory neurons (ORN) and the ~150 olfactory projection neurons (PN) implement primary olfactory habituation. In this essay, I’m essentially adding a second odor to the system. Although the fruit fly has separate habituation circuits for each of the 50 primary odors, it’s interesting to see what a shared habituation circuit might look like in the simulation.
Shared habituation pre-learning circuit
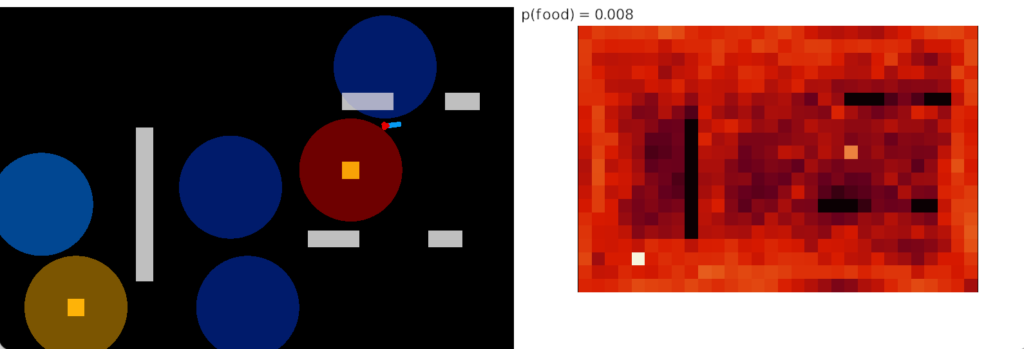
The simulation heat map shows the animal spends much of its time between the odor plumes because the habituation timeout keeps refreshing, despite encountering different odors. While habituation is active, the animal doesn’t approach either odor plume, but mostly moves in the default semi-random pattern. Only when habituation times out will it approach a new odor.
Shared habituation. Warm colors are food-predicting odors, blue are distractors.
Split habituation
The fruit fly has a split habituation unlike the previous simulation. Each primary odor has an independent habituation circuit, which is synapse specific.
Split habituation in pre-learning circuit
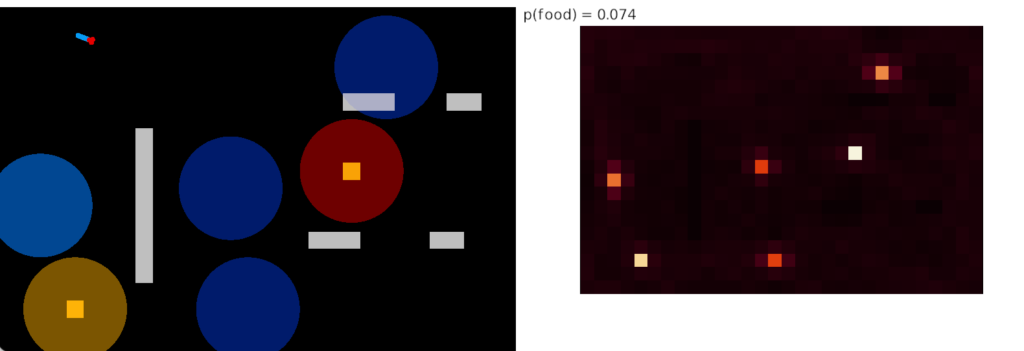
In the simulation of split habituation, the animal spends more time investigating the odors because each new odor has its own habituation timeout. It can move from a failed odor and immediately explore a new odor.
Simulation heat map for split habituation
Although the animal spends much of its time exploring the distractor candidate odors, it’s still a big improvement over random search, because it’s more likely to find food instead of a near miss.
Single distractor
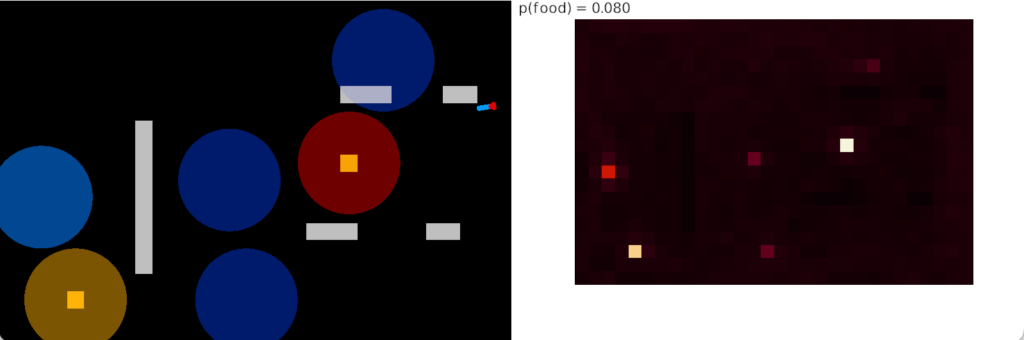
Since a single distractor exactly fits the single item cache, it’s unsurprising that adding the cache immediately solves the distractor problem. In the following heat map, the animal only explores the successful candidate odor and ignores the distractor.
Simulation heat map for single-item negative cache
Multiple odors and distractors
Multiple distractor odors is more interesting for a single item cache because it introduces miss-rate as a prominent issue and allows comparison between negative caching and positive caching (classical association). The table below is a summary of feeding time as a success metric for each strategy.
Algorithm
Feeding time
No odor approach
0.8%
No learning
7.4%
LTD (cache)
8.0%
LTP (classical)
5.7%
Success comparison for multiple algorithms, measured by feeding time
No odor approach
As a baseline, the first simulation disables all odor approach. The animal only reaches food when it runs into it randomly. While it’s above the food, the animal will slow, improving its efficiency somewhat. This strategy was explored in essay 14, and resembles the feeding of Trichoplax in [Smith et al. 2015].
Simulation heat map for odor-ignoring animal.
As the heat map shows, this strategy is pretty terrible. Because the animal only finds food by randomly crossing it, its success rate is purely a matter of the area covered by food. Although this strategy may have been effective with Precambrian bacteria mats, where finding food isn’t an issue, it’s a problem when finding food is a necessary task.
No learning
Intrinsic chemotaxis is important as a baseline for the learning strategies. In the fruit fly intrinsic odor approach behavior is in the lateral horn. When the MB is disabled, the lateral horn continues to approach odors.
Simulation heat map for non-learning odor-seeking animal.
As the above heat map shows, intrinsic odor approach is a vast improvement over non-chemotaxis, improving food time from 0.8% to 7.4% in this environment.
Negative caching (LTD)
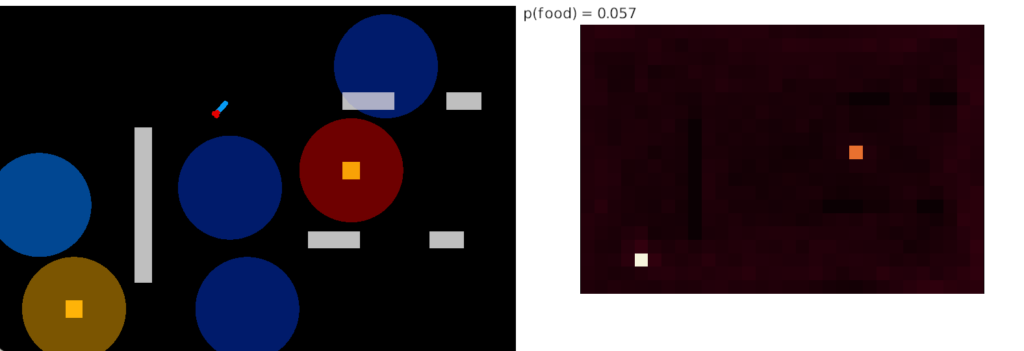
The single item caching that’s the focus of this post improves the food time from 7.4% to 8% by avoiding some of the time spent on non-food odors. The difference isn’t as dramatic as adding odor approach itself, but it’s an improvement.
Simulation heat map for single-item negative cache
In this strategy, the animal remembers the last failure odor, and ignores the odor plume the next time it reaches it. The animal explores all other odors, including failure odors. On a cache miss (failure), the animal remembers the new failure and forgets the old one.
Classical conditioning (LTP)
The next strategy tries to simulate what classical conditioning might look like if it was used for behavior. In this simulation, the animal only follows the odor after it’s associated with food, which means the animal needs to randomly discover the food first.
Simulation heat map for single-item classical association learning
This strategy is actually worse than the non-learning case, because it only finds one food source at a time. Although the heat map shows both being visited, the areas are actually alternating. One source is the only found food for a long time until the other is randomly discovered, when the roles switch and the first is now ignored.
Simulation limitations
I think it’s important to point out some simulation limitations, particularly since I’ve added performance numbers for comparison. The simulation environment and timings can affect the numbers dramatically. For example, the odor plume size dramatically affects the classical conditioning algorithm. If finding food without following the odor is difficult, the classical conditioning animal will have great difficulty finding a new odor.
Specifically, if the gain from following the odor is large, then classical conditioning will always have a penalty, because it loses out on that gain until it makes its association. In contrast an explore-first strategy will always gain the odor-exploring advantage. If the gain of explore-first outweighs its cost, then a non-learning explore-first will win against associative learning.
Consider the rough cache cost model above to see some of the issues with the negative cache. If the non-cacheable cost greatly outweighs the cache miss cost, then it doesn’t matter if the animal learns to avoid irrelevant odors. Contrariwise, if the miss cost is very large, then the miss rate is critical.
In addition, the miss rate is highly dependent on spatial and temporal locality. If similar odors are tightly grouped, even a small cache will have a low miss rate. But if there are many different distractor types spread randomly, the cache will miss most of the time.
Essay 15 is adding food-seeking to the simulated slug. Before the change in essay 14, the slug didn’t seek from a distance, but it does slow when it’s above food to improve feeding efficiency. The slug doesn’t have food-approach behavior, but it does have consummatory behavior. Because the slug doesn’t seek food, it only finds food when it randomly crosses a tile. Most of its movement is random, except for avoiding obstacle.
In the screenshot above, the slug is moving forward with no food senses and no food approach. Its turns are for obstacle avoidance. The food squares have higher visitation because of the slower movement over food. Notice that all areas are visited, although there is a statistical variation because of the obstacle.
Although the world is tiled for simulation simplicity, the slug’s direction, location, and movement is floating-point based. The simulation isn’t an integer world. This continuous model means that timing and turn radius matters.
The turning radius affects behavior in combination with timing, like the movement-persistence circuit in essay 14. The tuning affects the heat map. Some turning choices result in the animal spending more time turning in corners when the dopamine runs out. This turn-radius dependence occurs in animals as well. The larva zebrafish has 13 stereotyped basic movements, and its turns have different stereotyped angles depending on the activity.
Food approach
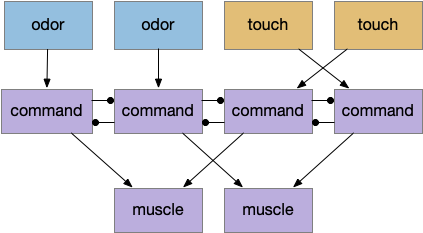
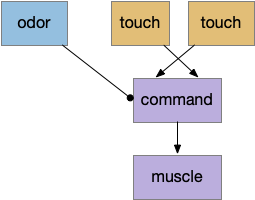
Food seeking adds complexity to the neural circuit, but it’s still uses a Braitenberg vehicle architecture. (See the discussion on odor tracking for avoided complexity.) Odor sensors stimulate muscles in uncrossed connections to approach the odor. Touch sensors use crossed connections to avoid obstacles. For simultaneous odor and touch, an additional command neuron layer resolves the conflict to favor touch.
The command neurons correspond to vertebrate reticulospinal neurons (B.rs) in the hindbrain. Interestingly, the zebrafish circuit does seem to have direct connections from the touch sensors to B.rs neurons, exactly as pictured. In contrast, the path from odor receptors to B.rs neurons is a longer, more complicated path.
For the slug’s evolutionary parallel, the odor’s attractively is hardcoded, as if evolution has selected an odor that leads to food. Even single-celled animals follow attractive chemicals and avoid repelling chemicals, and in mammals some odors are hardcoded as attractive or repelling. For now, no learning is occurring.
Perseveration (tunnel vision)
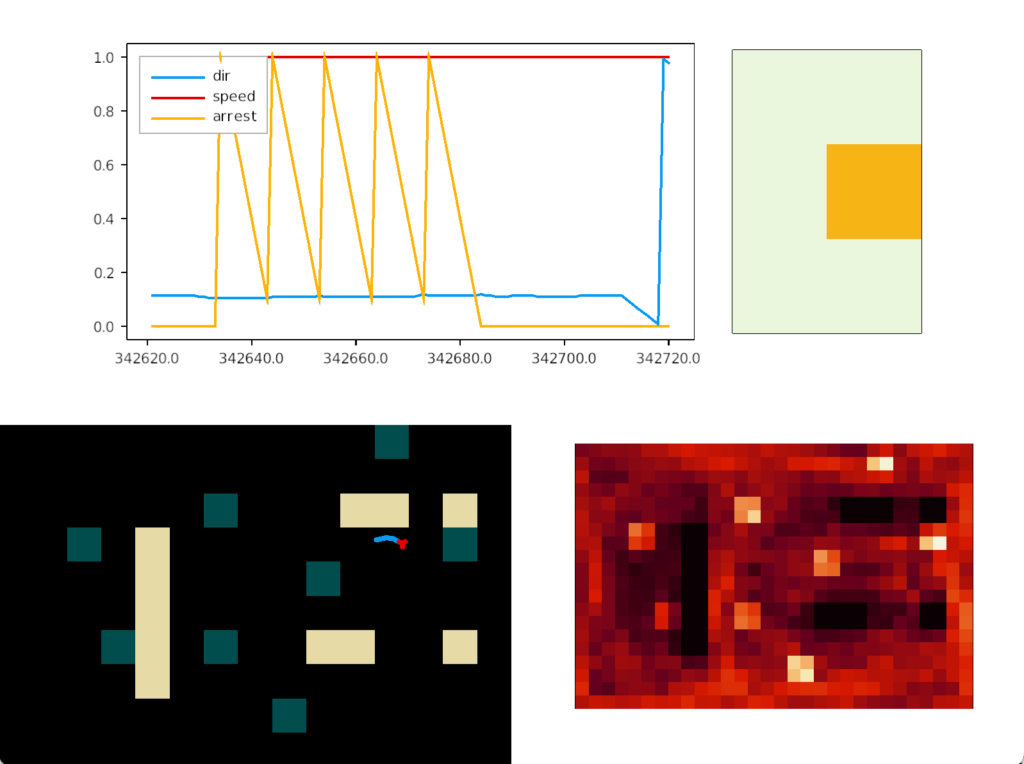
Unfortunately, this simple food circuit has an immediate, possibly fatal, problem. Once the slug detects an odor, it’s stuck moving toward it because our circuit can’t break the attraction. Although the slug never stops, it orbits the food scent, always turning toward it. The hoped-for improvement of following an odor to find food is a disaster.
In psychology, this inability to switch away is called perseveration, which is similar to tunnel vision but more pathological. Once a goal is started, the person can’t break away. In reinforcement learning terminology, the inability to switch is like an animal stuck on exploiting and incapable of breaking away to explore.
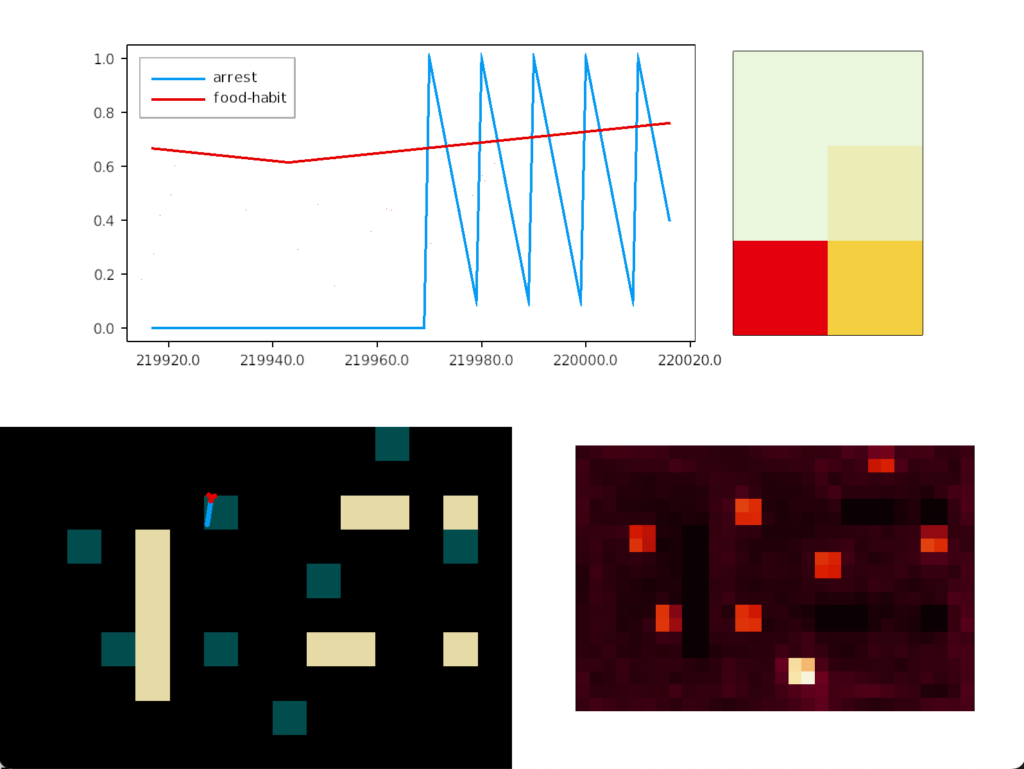
In the screenshot, the heat map shows the slug stuck on a single food tile. The graph shows the slug turning counter-clockwise, slowed down (sporadically arrested) over the food.
To solve the problem, one option is to re-enabled satiation for the simulation, as was added in essay 14, but satiation only solves the problem if the tile has enough food to satiate the animal. Unfortunately, the tile might have a lingering odor but no food, or possibly an evolutionary food odor that’s unreliable, only signaling food 25% of the time. Instead, we’ll introduce habituation: the slug will become bored of the odor and start ignoring it for a time.
In the fruit fly the timescale for habituation is about 20 minutes to build up and 20-40 minutes to recover. The exact timing is likely adjustable because of the huge variability in biochemical receptors. So, 20 minutes probably isn’t a hard constant across different animals or circuits for habituation, but more of a range between a few minutes or an hour or so.
Because the minutes to hour timescale for habituation is much wider than the 5ms to 2s range for neurotransmitters, the biochemical implementation is very different. Habituation seems to occur by adding receptors to increase receptor and/or adding more neurotransmitter generators to produce a bigger signal.
Fruit fly odor habituation
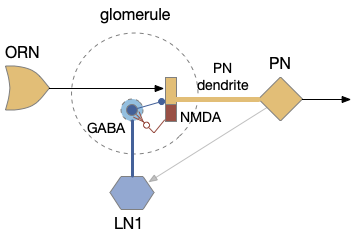
[Das 2011] studies the biochemical circuit for fruit fly odor habituation. The following diagram tries to capture the essence of the circuit. The main, unhabituated connection is from the olfactory sensory neuron (ORN) to the projection neuron (PN), which projects to the mushroom body. The main fast neurotransmitter for insects is acetylcholine (ACh), represented by beige.
The key player in the circuit is the NMDA receptor on the PN neuron’s dendrite, which works with the inhibitory LN1 GABA neuron to increase inhibition over time to habituate the odor.
The LN1 neuron drives habituation. Its GABA neurotransmitter release inhibits PN, which reduces the olfactory signal. Because LN1 itself can be inhibited, this circuit allows for a quick reversal of habituation. Habituation adds to simple inhibition by increasing the synapse strength (weight) over time when its used and decreasing the weight when its idle.
An NMDA receptor needs both a chemical stimulus (glutamate and glycine) and a voltage stimulus (post-synaptic activation, PN in this case). When activated, it triggers a long biochemical chain with many genetic variations to change synapse weight. In this case, it triggers a retrograde neurotransmitter (such as nitrous oxide, NO) to the pre-synaptic LN1 axon, directing it to add new GABA release vesicles. Because adding new vesicles takes time (20 minutes) and removing the vesicles also takes time (20-40 minutes), habituation adds longer, useful behavior that will help solve the odor perseveration problem.
Slug with habituation
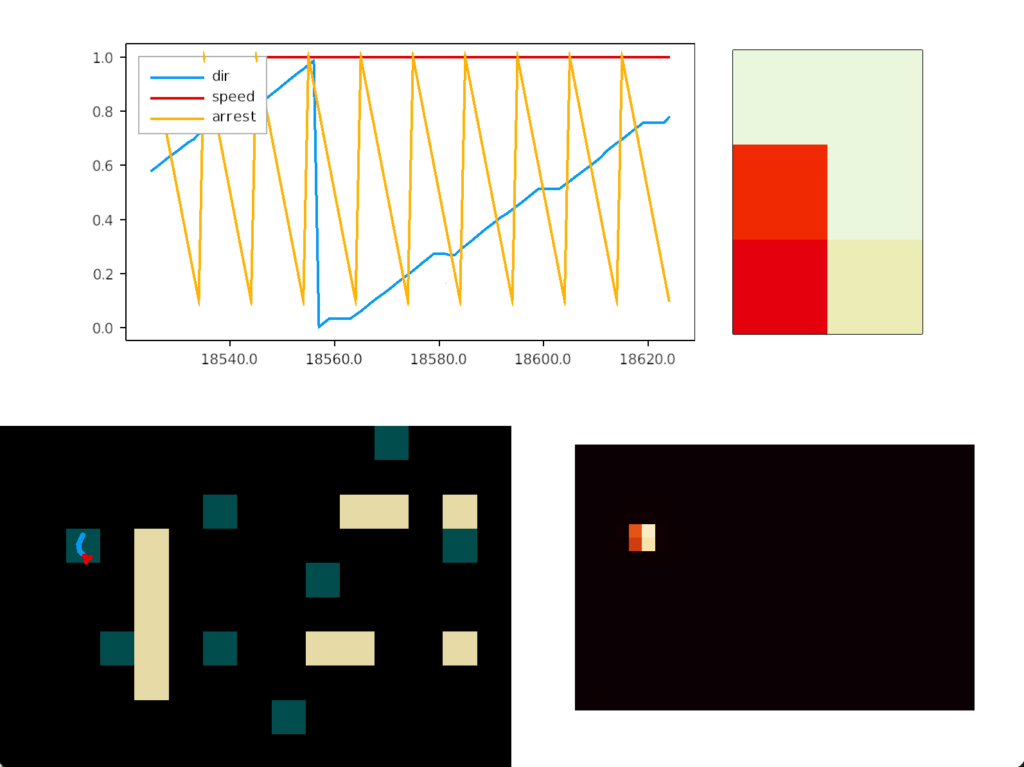
The next slug simulation adds trivial habituation following the example of the fruit fly. The simulation adds a value when the slug senses an odor and decrements the value when the slug doesn’t detect an odor. When habituation crosses a threshold, the odor sensor is cut off from the command neurons. The behavior and heat map look like the following:
As the heat map shows, habituation does solve the fatal problem of perseveration for food approach. The slug visits all the food nodes without having any explicit directive to visit multiple nodes. Adding a simple habituation circuit, creates behavior that looks like an explore vs exploit pattern without the simulation being designed around reinforcement learning. Explore vs exploit emerges naturally from the problem itself.
In the screenshot, the bright tile has no intrinsic meaning. Because habituation increases near any food tile, it can only decay when away from food. That bright tile is near a big gap that lets habituation to drop and recharge.
The essays aren’t designed as solutions; they’re designed as thought experiments. So, their main value is generally the unexpected implementation details or issues that come up in the simulation. For example, how habituation thresholds and timing affect food approach. The bright tile in the last heat map occurs because that food source is isolated from other food sources.
If the slug passes near food sources, the odor will continually recharge habituation and it won’t decay enough to re-enable chemotaxis. The slug needs to be away from food for some time for odor tracking to re-enable. In theory, this behavior could be a problem for an animal. Suppose the odor range is very large and the animal is very slow, like a slug. If simple habituation occurs, the slug might habituate to the odor before it reaches the food, making it give up too soon.
As a possible solution, the LN1 inhibitory neuron that implements habituation could itself be disabled, although that beings back the issue of the animal getting stuck. But perhaps it would instead be diminished instead of being cut off, giving the animal persistence without devolving into perseveration.
Odor vs actual food
Another potential issue is the detection of food itself as opposed to just its odor. If the food tile has food, the animal should have more patience than if the tile is empty with just the food odor. That scenario might explain why other habituation circuits include serotonin or dopamine as modulators. If food is actually present, there should be less habituation.
The issue of precise values raises calibration as an issue, because evolution likely can’t precisely calibrate cutoff values or calibrate one neuron to another. Some of the habituation and related synapse adjustment may simply be calibration, adjusting neuron amplification to the system. In a sense, that calibration would be learning but perhaps atypical learning.
Das, Sudeshna, et al. “Plasticity of local GABAergic interneurons drives olfactory habituation.” Proceedings of the National Academy of Sciences 108.36 (2011): E646-E654.
Shen Y, Dasgupta S, Navlakha S. Habituation as a neural algorithm for online odor discrimination. Proc Natl Acad Sci U S A. 2020 Jun 2;117(22):12402-12410. doi: 10.1073/pnas.1915252117. Epub 2020 May 19. PMID: 32430320; PMCID: PMC7275754.
Since essay 15 is exploring the fruit fly mushroom body, which is olfactory-focused, the simulated animal needs odor-based behavior, following attractive odors toward food. The simulation assumes an odor gradient navigation system without implementing the details. Basically, it will cheat and assume a direction vector toward the odor, because the details don’t seem to matter for the mushroom body.
In reality, the animal should use a timed gradient calculation with a single sensor (klinotaxis) or a directional navigation with multiple lateral sensors (tropotaxis). Simple animals use either navigation technique, and even bacteria can use klinotaxis with a run-and-tumble strategy.
The gradient itself is a big oversimplification for a marine slug as used in essay 15, because odors in water don’t have a simple gradient but clump instead. [Steele et al. 2023]. Since the odor plumes, clumps and filaments drive on the waters current, following the current upstream is a more effective than computing gradients.
To following a clumped odor plume in a water current, animals move upstream, against the flow toward the source. The navigation is based on the current flow mechanosensors, not an odor gradient. The odor sensing merely enables current following, which is an interesting circuit between chemosensory and mechanosensory circuits. Odor detection provides timing and go/no-go while the mechanosensory circuit navigates, somewhat like the “what” vs “where” split in the visual cortex.
In the diagram above, the odor control of the contra-flow navigation is inhibitory, a common pattern in vertebrate brain. For example, the striatum complex (basal ganglia) tonically inhibits its output, including midbrain locomotion or optic tectum. When an action is selected, the striatum disinhibits the midbrain command neurons. Despite the complication of disinhibition – double inhibition – the system improves signal noise.
When an inhibitory neuron disables a command, the added noise doesn’t matter because the behavior is disabled, and the extra control signal noise doesn’t harm the command. When the inhibitory control is taken away, the system has clean, undisturbed sensory data. As a contrast, in an excitatory system where the odor sensor positively excited the command, the odor control signal would add noise to the mechanical sensors, reducing precision. So, despite the extra complication of a double-negative inhibitory system, it’s behaviorally superior.
Essay 15 relevance
Although this odor navigation probably won’t be part of the essay 15 simulation, I think it’s important to describe what’s left out when simplifying a model. If the simulation becomes too simplified, it can lose the essence of the behavior. The simplification is necessary to keep the model uncluttered and focused, but the dividing line is a judgement call.
In the fruit fly Drosophila, the mushroom body is an olfactory associative learning hub for insects, similar to the amygdala (or hippocampus or piriform, O.pir) of vertebrates, learning which odors to approach and which to avoid. Although the mushroom body (MB) is primarily focused on olfactory senses, it also receives temperature, visual and some other senses. The genetic markers for MB embryonic development in insects match the markers for cortical pyramidal neurons and other learning neurons like the cerebellum granule cells.
While most studies seem to focus on the mushroom body as an associative learning structure, others like [Farris 2011] compare it to the cerebellum for action timing and adaptive filtering.
Essay 15 will likely expand the essay 14 slug that avoided obstacles, adding odor tracking. The mushroom body should show how to improve the slug behavior without adding too much complexity.
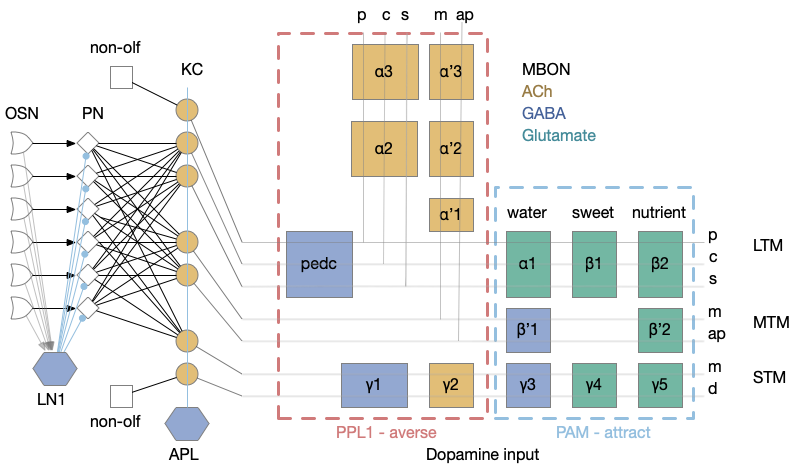
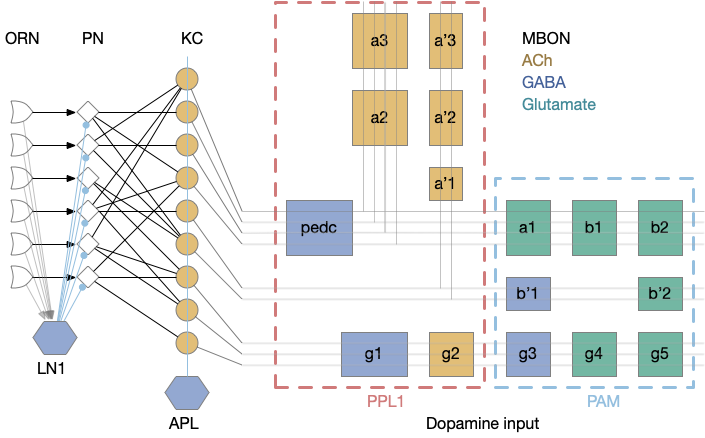
The mushroom body is a highly structured system, comprised of Kenyon cells (KC), mushroom body output neurons (MBONs), and dopamine (DAN) and optamine (OAN) neurons (collectively MBIN – mushroom body input neurons). The outputs are organized into exactly output compartments, each with only one or two output neurons (MBONs) [Aso et al. 2014].
Mushroom body architecture. Diagram adapted from [Aso et al. 2014].
The 50 primary olfactory neurons (ORN) and 50 projection neurons (PN) project to 2,000 KC neurons. Each KC neuron connects to 6-8 PNs with claw-like dendrites. The 2,000 KC neurons then converge to 34 MBONs. In vertebrates, divergence-convergence pattern occurs in the cerebellum with granule cells to Purkinje cells, in the hippocampus with dentate gyrus to CA3, in the striatum with MSN (medium spiny neurons) to S.nr/S.nc (substantia nigra), and in cortical areas with large granular areas.
Habituation (ORN, PN, LN1)
Olfactory habituation is handled by the LN1 circuit from the olfactory receptor neuron (ORN) to projection neuron (PN) connection. The fly will ignore an odor after 30 minutes, and the odor remains ignored for 30 to 60 minutes. Since the LN1 GABA inhibition neuron implements the habituation, suppressing LN1 can reverse habituation nearly instantly.
Habituation is odor-specific because it’s synapsed based, but a single neuron inhibits multiple odors. (There are multiple LN1 inhibitors, but they’re not odor-specific and inhibit multiple odors.) Habituation is odor-specific because it inhibits on a per-synapse system. LN1 doesn’t inhibit the PN, but inhibits the synapse from an ORN to the target PN. So, only figuring PNs trigger habituation, despite relying on a shared inhibitory neuron. [Shen 2020].
Sparse KC firing (KC, APL)
The 50 projection neurons (PNs) diverge into 2,000 Kenyon cells(KC). Each KC has 6-8 claw-like dendrites to 6-8 PNs. Each fly has a random connection between the PNs and its KCs. The KCs that fire for an odor form a “tag,” which is essentially a hash of the odor inputs.
About 5% of the KCs fire for any odor, which is strictly enforced by the APL circuit. APL is a single inhibitory GABA neuron per side that reciprocally connects with all 2,000 KCs. The APL inhibition threshold ensures only the strongest 5% of KCs will fire.
A computer algorithm by [Dasgupta et al. 2017] uses this KC tag for a “fly hash” algorithm, which computes a hash using a random, sparse connection for locality-sensitive hashing (LSH). LSH retains information from the origin data to retain distance between hashes as reflective as distance between odors. Interestingly, they use the fly hash with visual input, treating pixels as equivalent to odors. Despite the significant differences between unique odors and arbitrary pixels, the results for the fly hash are better than other similar LSH systems.
Dopamine and compartments (MBON, DAN)
The output compartments for the mushroom body are broadly organized into attractive and repellant groups with seven repelling compartments and nine attracting compartments. Three of the compartments (g1-g3) feed forward into other compartments.
Each compartment is fed by one or two dopamine neuron types (DAN), for a total of 20 DAN types for 16 MBON compartments. The repellant section (PPL1) is even more restricted with exactly one dopamine neuron per compartment. The attractive section (PAM) has a bound 20 DAN cells per compartment.
In a study of larval Drosophila [Eichler et al. 2020] studied the entire connectome of the mushroom body and found highly specific reciprocal MBON connections, inhibitory, directly excitatory and axon excitatory.
An [Eschbach et al. 2020] study looked at dopamine (DAN) connective. Each DAN type has distinct inputs from raw value stimuli (unconditioned stimuli – US), and also internal state, and feed back from the mushroom body. So, while the DANs do convey unconditioned stimuli for learning, they’re not a simplistic reward and punishment signal.
Essay 15 simulation direction
Essay 15 will likely continue the slug-like animal from essay 14, and add odor approaching. Because I think the slug will need habituation immediately, I’ll probably explore habituation first.
The essay will probably next explore a single KC to a single MBON, simulating a single odor.
I’m tempted to explore multiple MBON compartments before exploring multiple KCs. Partially for general contrariness: pushing against the simple reward/punishment model to see if it goes anywhere, or if multiple dopamine sources needlessly complicated learning.
And, actually, since I want to push against learning as a solution for everything, to see how much of the mushroom body function can work without any learning at all, treating habituation as short term memory, not learning.
References
Aso Y, Hattori D, Yu Y, Johnston RM, Iyer NA, Ngo TT, Dionne H, Abbott LF, Axel R, Tanimoto H, Rubin GM. “The neuronal architecture of the mushroom body provides a logic for associative learning.” Elife. 2014 Dec 23;3:e04577. doi: 10.7554/eLife.04577. PMID: 25535793; PMCID: PMC4273437.
Dasgupta S, Stevens CF, Navlakha S. “A neural algorithm for a fundamental computing problem.” Science. 2017 Nov 10;358(6364):793-796. doi: 10.1126/science.aam9868. PMID: 29123069.
Eichler, Katharina, et al. “The complete connectome of a learning and memory centre in an insect brain.” Nature 548.7666 (2017): 175-182.
Eschbach, Claire, et al. “Recurrent architecture for adaptive regulation of learning in the insect brain.” Nature Neuroscience 23.4 (2020): 544-555.
Farris, Sarah M. “Are mushroom bodies cerebellum-like structures?.” Arthropod structure & development 40.4 (2011): 368-379.
Shen Y, Dasgupta S, Navlakha S. “Habituation as a neural algorithm for online odor discrimination.” Proc Natl Acad Sci U S A. 2020 Jun 2;117(22):12402-12410. doi: 10.1073/pnas.1915252117. Epub 2020 May 19. PMID: 32430320; PMCID: PMC7275754.
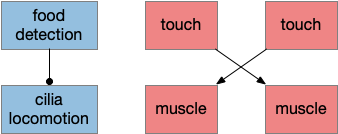
When the simulated slug hits an obstacle straight-on, both sensors fire, which forces an arbitrary choice between turning left and right. The simple Braitenberg circuit doesn’t handled the conflict. And, because of timing and inertial, the slug could start turning right, hit both sensors and switch to a left turn. My prior solution for the problem chose one direction to win, which does work but has problems of its own.
In a natural setting where the animal needs to flee from predators, a predictable route is dangerous. When a zebrafish larva escapes, it chooses left or right randomly. The choice itself doesn’t matter; it’s the unpredictability of a random choice that matters. Unfortunately, the simple circuit doesn’t solve the problem.
Using muscles for timing
One problem is a lack of memory or internal state to make the choice stick. Without memory, and with random choice, the animal chooses again and again, because the previous choice doesn’t lock out the next one. Since both sensors are active, the animal chooses left or right randomly, but 10ms (or one tick) later it notices both sensors active and chooses again. It can’t stick to its decision. Because the animal doesn’t’ have a cortex or any complicated recurrent circuit at all, it doesn’t have working memory in the psychological sense. Besides, a complicated hundreds-of-neurons solution is overkill for this problem, as well as being evolutionarily implausible.
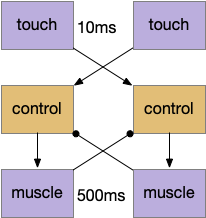
Because it’s a timing problem, and biology is a master of chemistry, either a chemical or a mechanical solution is easier than a circuit solution. A glutamate neuron with a fast receptor (AMPA, for example), is around 5-10ms, which is far too short for physical behavior. I need something in the 500ms range.
The muscle itself is one possible memory source, since the muscles and body motion is what I’m trying to control. Essentially, using physical timing. If a proprioceptive signal from the active muscle could inhibit the opposite muscle, the muscle’s own activity would force a follow-through, avoiding the high-frequency oscillation of random choice.
The controller code only fires the muscle if the opposite muscle isn’t firing. There are separate controllers for the left and the right.
While muscle proprioception for memory works, it’s limited to near the muscle. Another option in the 500ms range is to use monoamines like dopamine, serotonin, noradrenaline, or to use acetylcholine (ACh), all of which have receptors in the 50-500ms range.
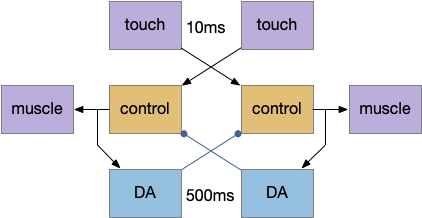
A possible circuit might borrow from the muscle circuit, using dopamine for memory. Instead of the muscles providing negative feedback, a dopamine neuron receives a collateral from muscle activation. The target command interneuron has an inhibitory DA receptor (D2), which prevents it from firing.
Using dopamine instead of serotonin in this example is mostly arbitrary because many action-related systems use serotonin, and both neurotransmitters have multiple receptor types for both excitation and inhibition. I’m using DA here because of some parallels with the striatum (basal ganglia.)
One of the functions of the striatum/basal ganglia is to lock in choices, like I need here. Once locked-in, the choices need some way of unlocking, such as for a new danger or a new opportunity, or simply to prevent the animal from getting stuck. Here, I’m using the chemical decay to timeout the locked-in choice. In the striatum, ACh neurons and specific thalamic input (specifically T.pf) breaks the current choice and pauses input, allowing for choice switching. This sophisticated attention-breaking system implies that it’s breaking an existing attention-retention system. So, it’s at least conceivable that and attention system like I’m exploring here might have been one of the initial, primitive sources for striatal function.
As a coding matter, if the example were any more complicated I’d need to refactor this into something more abstract.
The decay simulates the chemical and receptor signal decay. The two actions are axon collaterals: firing the muscle and activating dopamine. The semi-complicated dopamine assignment simulates a refractory period, where the dopamine can’t fire until its decay is complete. The current code works for a single instance, but it would get annoying for multiple controllers.
The same might be true for evolution. Evolving this system once is plausible, but repeating it for every instance would be difficult, which might explain the evolution of a system like the striatum as a single solution to a repeated problem.
Avoiding positive feedback
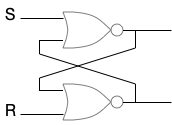
I’ve avoided using positive feedback deliberately. First, because I think it’s too large of a step for evolution to create for such a simple system. Second, because positive feedback can get stuck without the addition of a reset signal, which again is too much to ask of evolution. Both the muscle timing and chemical timing solutions are capabilities already available, are more robust, and are simpler solutions.
The set-reset latch above shows some of the complexities. The latch needs both a set and a reset signal. Unless there’s some mechanism to reset the latch, it’s not practical. But adding a reset is another step for evolution, and to add both the feedback and a reset simultaneously is a difficult ask.
Second, the electrical latch works because it can maintain two constant digital values. Either is a stable state. A neuron only has one stable state and sends signals with pulses, and early neurons were likely exceptionally noisy. So, there’s a good chance for an ON signal to get lost just because of noise. Or, if the gain is exceptionally high to keep the ON, then noise might generate a spurious signal.
Now, feedback signals do exist in the brain — the hippocampus CA3 is an important example — but those have a far greater complexity than the simple slug I’m considering here. For example, there’s a sophisticated entire dual clocking system (theta and gamma) and ACh reset system in CA3 [Hasselmo 2006].
Hasselmo ME. The role of acetylcholine in learning and memory. Curr Opin Neurobiol. 2006 Dec;16(6):710-5. doi: 10.1016/j.conb.2006.09.002. Epub 2006 Sep 29. PMID: 17011181; PMCID: PMC2659740.