A problem with essay 17 was the lack of action stickiness, which became a problem for avoiding obstacles. When the animal hits an obstacle head-on, both touch sensors fire and the animal chooses a direction randomly. Because the decision repeats every tick (30ms) and chooses randomly to break ties, the animal flutters between both choices and remains stuck until enough random choices are in the same direction to escape the obstacle. What’s needed is a stick choice system to keep a direction once it’s selected. In some decision studies, this is a “win-stay” capability.
A previous essay solved this issue with muscle-based timing or a dopamine-based system, but some of the theories of the striatum function suggest it might solve the problem. The core idea uses the dopamine as a feedback enhancer to sway choice to “stay.”
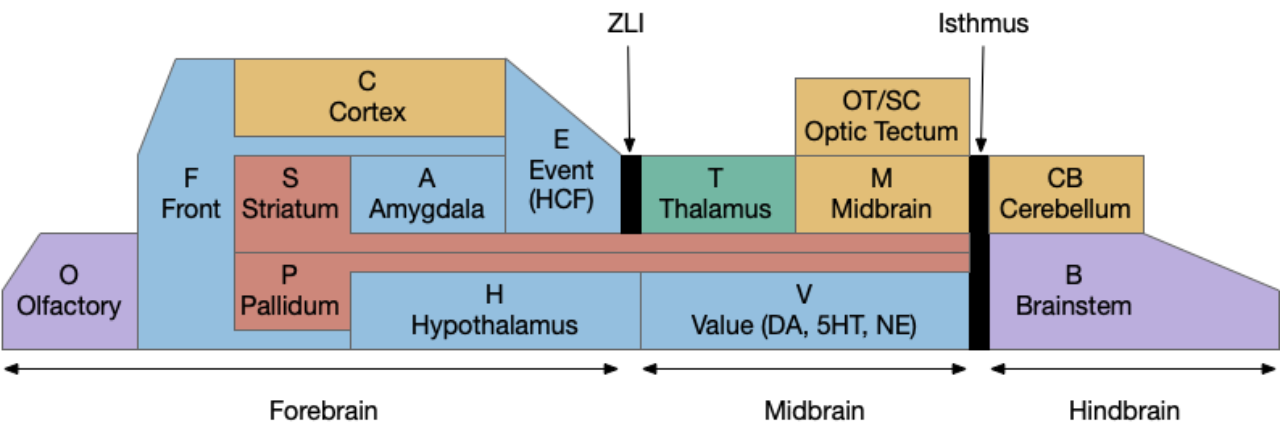
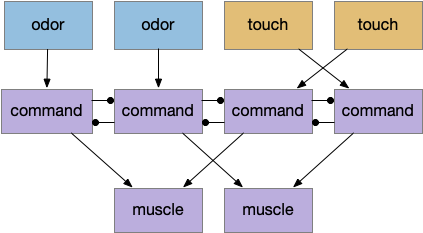
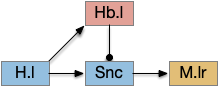
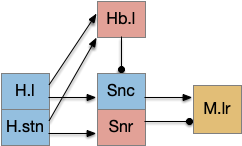
Simplified proton-striatum circuit for “win-stay.” B.ss somatosensory (touch), B.rs reticulospinal motor control, M.lr midbrain locomotive region, S.pv parvalbumin GABA inhibitory interneuron, Snc substantia nigra pars compacta, S.spn striatum spiny projection neuron (aka medium spiny neuron), ACh acetylcholine, DA dopamine.
The circuit is intended not as the full vertebrate basal ganglia, but a possible core function for a pre-vertebrate animal in the early Cambrian. The circuit here represents only the direct path and specifically only the striostome (patch) circuit, and only represents the downstream connections, and ignores the efferent copy and upstream enhancements. Despite being simplified, I think it’s still to complicated as a single evolutionary step.
Simplified proto-circuit
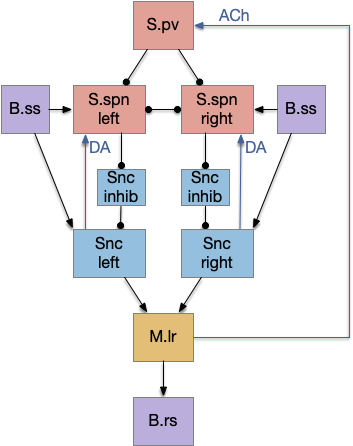
If that simplified striatal circuit is too complicated for an evolutionary step, but lateral inhibition is a reasonable circuit.
Simplified photo-circuit with lateral inhibition.
The above simplified circuit is a simple lateral inhibition circuit with an added reset function from the motor region.
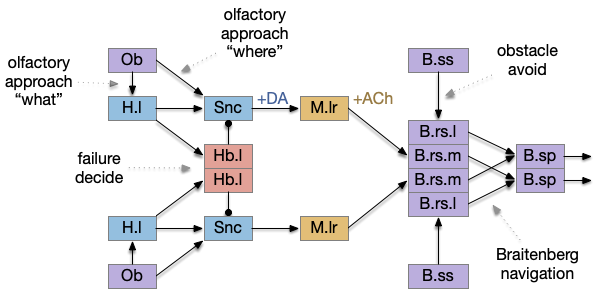
The main path is through the somatosensory touch (B.ss), through the substantia nigra pars compacta (Snc – posterior tubuculum in zebrafish) to the midbrain locomotive region (M.lr). [Derjean et al. 2010] traced a similar path for olfactory information. I’m just replacing odor with touch.
The reset function might be a simple efferent copy from the central pattern generator for timing. In a swimming animal like an eel, the spinal cord controls the oscillation of body undulation, moving the animal forward. Because the cycle is periodic, when the motor system fires at a specific phase such as an initial-segment muscle twitch, it can send a copy of the motor signal upstream as an efferent copy. That signal is periodic, clock-like, something like the theta oscillation in vertebrates, and upper layers can use that clock.
Zebrafish larva swim in discrete bouts, each on the order of 500ms to 2sec. Since the specific mechanism that organizes bouts isn’t known, any model is just a guess, but might motivate some of the striatal circuitry. Specifically, the acetylcholine (ACh) path in the striatum. The motor swimming clock could break movement into bouts with a reset signal.
Since the sense to Snc to M.lr is a known circuit [Derjean et al. 2010], lateral inhibition is a common circuit, and motor efferent copy of central pattern oscillation is also common, this simplified circuit seems like a plausible evolutionary step.
Improved circuit
Some problems in the simplified circuit lead to improvements in the full circuit. The simplified circuit is susceptible to noise, leading to twitchy behavior, because sensors and nerves are noisy. Secondly, when two options compete, a weaker signal might win the competition if it arrives first. An accumulator system that averages the signals will give better comparisons.
To improve the decisions, the new circuit adds a single pair of inhibition neurons, specializes the existing neurons, and changes the connections.
Circuit improving noise and decision.
To improve decision making, the S.spn neurons are now accumulators, averaging inputs over 100ms or so, just long enough to reduce noise without harming response time too much. As an implementation detail, the S.spn neurons might either accumulate calcium (Ca) itself, or a partner astrocyte might accumulate Ca.
To improve noise behavior, the added Snc inhibition neurons tonically inhibit the Snc neurons, so a stray signal from B.ss to Snc won’t inadvertently trigger the action before the decision. The dual inhibition is a slightly complicated circuit which reduces noise because an active path (disinhibited) has only sense inputs; the modulatory signals are taken away.
The dopamine feedback has the benefit of being a modulator instead of a pure feedback signal. Because it’s a multiplicative modulator, dopamine doesn’t trigger the cycle itself. When the signal ends, the dopamine feedback doesn’t continue a ghost reverberation signal.
Choice decisions: drift diffusion
Psychologists, economists, and neuroscientists have several useful models for decision making, primarily deriving from the drift diffusion model [Ratcliff and McKoon 2008], which extends a random walk model to decision-making. While most of the research appears to be centered on visual choice in the cortical (C) visual system, such as the lateral intraparietal area (C.lip), the concepts are general and the circuits simple, which could apply to many neural circuits, even outside of the mammalian cortex.
Drift-diffusion is a variation of a random walk. Each new datum adds a vector to an accumulator, walking a step, until the result crosses a threshold.
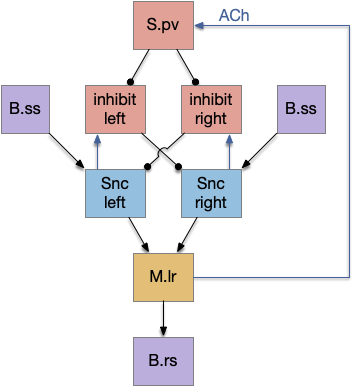
Circuits for leaky competing accumulator (LCA) and feed-forward models of two-choice decision.
One simple model is the leaky competing accumulator (LCA) of [Usher and McClelland 2001], where each choice has an accumulator, and the accumulators inhibit each other laterally. Another model use feedforward inhibition instead of lateral inhibition, where each sense inhibits its competitors. For this essay, these models seem a good, simple options for the simulation.
In the context of the striatum, [Bogacz and Gurney 2007] analyze the basal ganglia and cortex as a choice-based decision system. They interpret the direct path (S.d1) as the primary accumulator, and the indirect path (S.d2 / P.ge / H.stn) as feed-forward inhibition. They suggest that the basal ganglia could produce near-optimal decision in the two-choice task.
While implementing the basic model, some issues came up, including issues already solved in earlier essays.
What controls “give-up”?
The foraging task needs to give-up on a non-promising odor, ignore it, leave from the current place, and explore for a new odor. In an earlier essay, odor habituation implemented give-up. If the seek didn’t find the food within the habituation time, the sense would disappear, disabling the seek action.
Animal circling food with no ability to break free.
The perseveration problem can be solved in many ways, including the goal give-up circuit in essay 17 and the odor habituation in an earlier essay. One approach cuts the sensor; the other disables the action. But two solutions raises the question of more possible solutions, any or all of which might affect the animal.
Sense habituation (cutting sensor)
Habenula give-up (inhibit action)
Motivational state – hypothalamus hunger/satiety
Circadian rhythm – foraging at twilight
Global periodic reset – rest / sleep
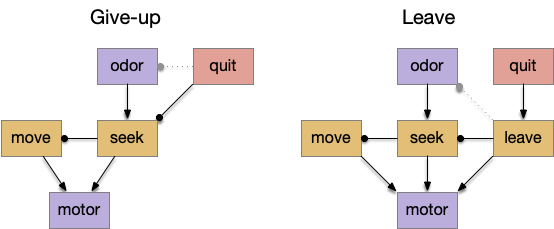
Give-up or leave?
The distinction between giving-up and leaving is between abandoning the current action and switching to a new, overriding action. Although the effect is similar, the implementing circuit differs. In a leave circuit, after the give-up time, the animal would actively leave the current area (place avoidance). Assuming the leave action has a higher priority than seeking, then lateral inhibition would disable the seek action. In foraging vocabulary, does failure inhibit exploitation or does it encourage exploration?
Distinct circuits for give-up and leave to curtail a failed odor approach.
As the diagram above shows, this distinction isn’t a semantic quibble, but represents different circuits. In the give-up circuit, the quit decision either inhibits the olfactory seek input and/or inhibits the seek action. With seek disable, the default action moves the animal away from the failed odor. In the leave circuit, the quit decision activates a leave action, which moves the animal away from the failed place, inhibiting the seek action laterally.
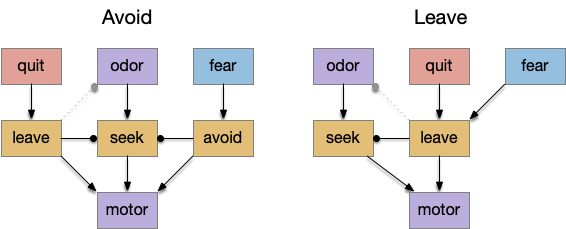
Leave or avoid?
Leaving an area is a primitive action and is a requirement for foraging. However, neuroscience papers don’t generally study foraging, they study place avoidance from aversive stimuli, which raises a question. Since the physical action of leaving and aversive place avoidance is identical, do the two actions share circuits or are they distinct?
Distinct leave and avoid actions compared to shared locomotion.
In the avoid circuit, danger avoidance is distinct from food-seeking, only sharing at the lowest motor layers. In the leave circuit, exploration leaving and place avoidance share the same mid-locomotor action.
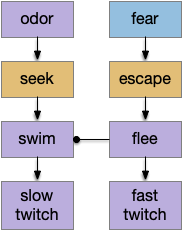
Slow and fast twitch swimming
[Lacalli 2012] explores the evolution of chordate swimming, inspired by a discovery of mid-Cambrian fossils, which suggest that fast-twitch muscles are a later addition to a more basal chordate swimming, possibly to escape from new Cambrian predators. The paper explores the non-vertebrate Amphioxus motor circuitry in like of the fossil, suggesting two distinct motor circuits: normal swimming and escape.
Slow and fast paths for normal swimming and fast predator escape.
In this model, higher layers are independent paths that only resolve at the lowest motor command neuron level (such as B.rs). For the foraging tasks, this model that leaving an explored area would use a different system from leaving a noxious area (place aversion), despite being the same underlying motion.
Serotonin as muscle gain-control
In the zebrafish, [Wei et al. 2014] studied serotonin in V.dr (dorsal raphe) as gain-control for muscle output, amplifying the effect of glutamate signals. When they inhibited 5HT (serotonin), the muscle only produced 40% of its maximal strength. Serotonin acted as a gain-control, a multiplicative signal that amplified glutamate signals, allowing for a broader dynamic range.
[Kawashima et al. 2016] investigated 5HT in the context of task-learning for muscle effort, where 5HT caches the real-time adjustment by the cerebellum and pretectal areas. When 5HT is disabled, the real-time system still adjusts the muscle effort, but it doesn’t remember the adjustment for future bouts. That study considers the 5HT neurons as leaky integrators of motor-gated visual feedback, where zebrafish gauge the success of swimming effort by visual motion. Notably, the neurons only store visual information when the fish is actively swimming, as an action-outcome integrator.
The two studies focused on opposite muscle effects, both increasing effort and decreasing effort. 5HT can either inhibit or excite depending on the receptor type, suggesting that 5HT shouldn’t be interpreted as representing a specific value, either positive or negative, but instead possibly carrying either value.
Taking these studies as analogies, it seem reasonable to consider V.dr as an action-outcome accumulator for future effort in the 10-30 seconds range, not specific to either positive or negative amplification. Of course, because serotonin has diverse effects in multiple circuits, reality is likely more complicated.
Serotonin zooplankton dispersal and learning
Many aquatic animals have a larval zooplankton stage, where the larva disperses from its spawn point for several days or weeks, then descends to the sea floor for its adult life. A small number of serotonin neurons signal the switch to descend. Essentially, this is a single explore/exploit pair.
Larva exploring in a dispersal stage, switching to descend to the sea floor for adult life.
Habenula function circuit
Essay 17 is running with the model of the habenula as central to the give-up/move-on circuit. The following is a straw man model of the habenula based on the above discussion of quitting, leaving and avoiding circuits. Because essay 17 has no learning or higher areas like the striatum, the diagram ignores any learning functionality. This diagram is for a hypothetical pre-stratal habenular function.
Odor-based locomotion using the habenula.
Note, this locomotion only includes odor-based navigation. The audio-visual-touch locomotion uses a different system based on the optic tectum. This dual-locomotive system may be the result of a bilaterian chimaera brain [Tosches and Arendt 2013].
The habenula connectivity and avoidance path is loosely based on [Stephenson-Jones et al. 2012] on the lamprey habenula connectivity. The seek path is loosely based on [Derjean et al. 2010] for the zebrafish.
In this model, Hb.m (medial habenula) is primarily a danger-avoidance circuit, and M.ipn (interpeduncular nucleus) is a place avoidance locomotive region. Hb.l (lateral habenula) is a give-up circuit that both inhibits the seek function (giving up) and excites the shared leave locomotor region, implementing the foraging exploit to explore decision. Here, place avoidance and exploratory leaving are treated as equivalent. As mentioned above, this diagram is mean to be a straw man or a thought experiment, because it’s easier to work with a concrete model.
The locomotive model in essays 14 to 16 were non-vertebrate. Essay 17 takes the same problems, avoiding obstacles and seeking food, and with a model based on the vertebrate brain. Since these models are still Precambrian or early Cambrian, they don’t include the full vertebrate architecture, but try to find core components that might have been a basis for later vertebrate developments.
The animal is a slug-like creature with mucociliary forward movement, where propulsion is cilia or cilia-like and steering is muscular. This combination of slug-like motion and vertebrate brain is probably not evolutionary accurate, but it allows touch-based obstacle avoidance without the complications of vision of lateral-line senses.
The animal seeks food by following odor plumes, and avoids obstacles by turning away when touching them. The locomotion model includes the following components:
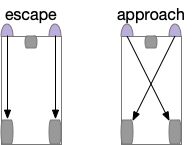
[Braitenberg 1984] navigation (simple crossed vs uncrossed signals for approach and avoid).
Obstacle avoidance with a direct touch-to-muscle circuit.
Odor-seeking with distinct “what” and “where” paths.
Perseveration fix with an explicit give-up circuit.
Motivation-state (satiety) control of odor-seeking (“why” path [Verschure et al. 2014])
Proto-vertebrate model
A diagram of the proto-vertebrate model, including analogous brain regions follows:
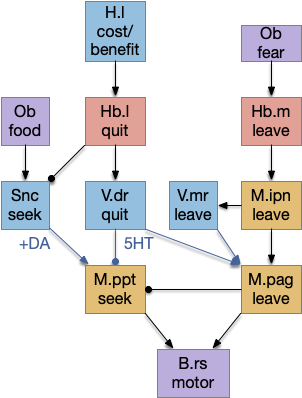
Proto-vertebrate locomotive model. Key: B.sp spinal motor, B.rs reticulospinal motor command (medial and lateral), B.ss spinal somatosensory, H.l lateral hypothalamus, Hb.l lateral habenula, M.lr midbrain locomotive region (M.ppt), Ob olfactory bulb, Snc substantia nigra pars compacta. DA dopamine, ACh acetylcholine.
For the sake of readability, the model simplifies the actual vertebrate midline crossing patterns, leaving only a single cross between B.rs (reticulospinal) and B.sp (spinal), which represents Braitenberg navigation.
In this model, obstacle avoidance is reflexive between B.ss (somatosensory touch) and B.rs. Odor navigation (“where”) flows through Snc (substantia nigra pars compacta) to M.lr (midbrain locomotive region). In the zebrafish, the Snc area is the posterior tuberculum, and the M.lr like represents M.ppn (pedunculopontine tegmental nucleus). The motivation-state (hunger or satiety) and “what” (food odor vs non-food) flow through H.l (lateral hypothalamus). The give-up circuit flows through Hb.l (lateral habenula).
Olfactory navigation path
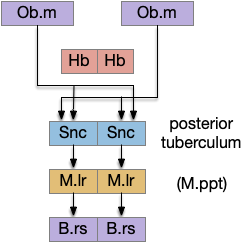
[Derjean et al. 2010] traced a path in zebrafish from Ob (olfactory bulb) to the posterior tuberculum (mammal Snc) to the midbrain locomotive region (likely M.ppn), to the reticulospinal motor command neurons.
Zebrafish olfactory to motor path in [Derjean 2010].
I’ve labeled this path as a “where” path, based on simulation requirements, but as far as I know, that label has no scientific basis.
The Snc / posterior tubuculum area includes descending glutamate and dopamine (DA) neurons, although the Snc is better known for its ascending dopamine path. Since [Ryczko et al. 2016] reports a mammalian descending glutamate and DA path from Snc to M.ppn, portions of this descending path appears to be evolutionarily conserved. The DA appears to be an effort boost, increasing downstream activity, but most of the activity is glutamate.
Braitenberg navigation
[Braitenberg 1986] vehicles are a thought experiment for simple circuits to implement approach and avoid navigation. In the original, the vehicles have two light-detection sensors connected to drive wheels. Depending on the connection topology, sign and thresholds, the simple circuits can implement multiple behaviors.
Braitenberg circuits for approach and escape.
A circuit that combines the output of approach and avoid circuits with some lateral inhibition can implement both approach and avoidance with avoidance taking priority. In the essay simulation, if the animal touches a wall, it will turn away from the obstacle, temporarily ignoring any odor it might be following.
Circuit for combined odor approach and touch obstacle avoidance.
Mammalian locomotion appears to use a similar circuit between the superior colliculus (OT – optic tectum) and the motor driving B.rs neurons [Isa et al. 2021]. This circuit pattern implies that approach and avoidance are separate behaviors, only reconciled at the end. For example, a punishing reinforces that increases avoidance is not simply the mirror image of a non-reward that decreases approach. The two reinforcers modify different circuits.
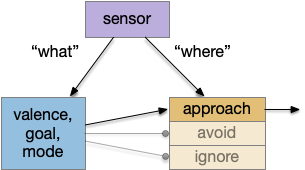
“What” path vs “where” path
The mammalian visual system has separate “what” and “where” paths. One path detects what object is in focus, and one path keeps track of where the object location is. This division between object decision and navigation has been useful in the simulation, because navigation details are quickly lost in the circuit when deciding what to do with an odor.
“What” and “where” paths as configuring a switchboard.
When an animal senses an odor, say a food odor, the animal needs to identify it as a food odor, decide if the animal is hungry or sated, and decide if there’s a higher-priority task. All that processing and decision can lost the fine timing phase and amplitude details needed for precise navigation. Gradient following, for example, needs fine differences in timing or amplitude to decide whether to turn left or right. By splitting the long, complicated “what” decision from the short, simple “where” location, the circuit can benefit from both.
[Cohn 2015] describes the fruit fly mushroom body as a switchboard, where dopamine neurons configure the path for olfactory senses to travel. In the context of “what” and “where”, the “what” path configures the switchboard and the “where” path follows the connected circuit.
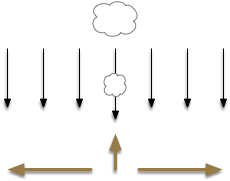
Some odor-based navigation has a more extreme division between “what” and “where.” Following odor in water isn’t always gradient-based navigation, because odors form clumps instead of gradient plumes. Instead of following a gradient, the animal moves against the current toward the odor source. In that latter situation, the “where” path uses entirely different senses for navigation, using water flow mechanosensors, not olfactory sensors [Steele et al. 2023].
Navigation against current toward an odor plume.
The diagram above illustrates a food-searching strategy for some animals in a current, both water and air. In water, the current is more reliable for navigation than an odor gradient. When there’s no scent, the animal swims back and forth across the current. When it detects a food odor, it swims against the current. If it loses the odor, it will return to back and forth swimming. In this navigation type, entirely different senses drive the “what” and “where” paths.
Foraging and give-up time
Giving up is an essential part of goal-directed behavior. If an animal cannot ever give up, it will be stuck on the goal without escaping. In the context of foraging, the give-up time is optimized with the marginal value theorem [Charnov 1976], suggesting that an animal should move to another patch when its current reward-gaining rate drops below the average rate for the environment. Animal behavior researchers like [Kacelnik and Brunner 2002] have observed animals roughly following this theorem, although using simpler heuristics.
In more complex animals, the failure to give up can be pathological, such as psychological perseveration.
Foraging state diagram illustrating the give-up timer
The give-up circuit needs some kind of internal timer or cost integrator, and a way to cancel the task. In this essay’s model, the lateral habenula (Hb.l) computes the give-up time or integrates the cost, and it cancels the task by suppressing the locomotive signal through Snc.
Habenula as a give-up circuit
Hb.l is positioned to act as a give-up circuit. It receives cost signals as non-rewarded bouts or as aversive events. [Stephenson-Jones et al. 2016] interprets the Hb.l input, P.hb (habenular-projecting pallidum), as evaluating action outcome. Hb.l can suppress both the midbrain dopamine and midbrain serotonin areas. In learned helplessness situations or depression, Hb.l is hyperactive [Webster et al. 2020], causing reduced activity.
Habenula circuit as a give-up mode in a locomotive circuit.
[Hikosaka 2012] suggests the habenula’s role as suppressing motor activity under aversive conditions, a role evolved from its close relationship to the pineal gland’s circadian scheduling.
In a review article, [Hu 2020] discusses the suppressive effects of the habenula, also remarking on its role as a reward-prediction error. In particular, noting that H.l (lateral hypothalamus) to Hb.l is aversive. The Hu article also notes that Hb.l knock-out abolishes the error signal from reward omission, not an error signal from aversive (shock or obstacles).
Once the threshold is crossed, the Hb.l to Snc signal produces behavioral avoidance, reduced effort and depressive-like behavior from learned helplessness. The Hb.l is the only brain area consistently hyperactive in animal models of depression.
Note, since this essay’s simulation is a non-learning behavioral model, the only “prediction” possible is an evolutionary intrinsically-attractive odor, and the only role for an error is giving up the current behavior. Here, I’m interpreting the H.l to Hb.l signal as a cost signal, integrated by Hb.l, that gives up when it crosses a threshold.
Vertebrate reference
For reference, here’s a functional model of the vertebrate brain.
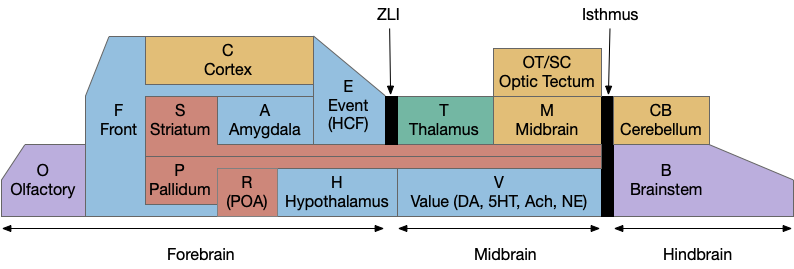
Functional model of vertebrate brain.
The areas in this model cluster around the hindbrain isthmus divider. B.rs are hindbrain neurons near the isthmus. M.lr (M.ppn) are midbrain neurons that migrate from the hindbrain (r1) to the midbrain. Snc is the midbrain tegmental area (the V – value area), near the isthmus, and contiguous with M.ppn. Similarly the H.l area that projects to Snc is contiguous with it. The habenula is the most distant area, located above the thalamus near the pineal gland (not in the diagram as a simplification, but associated with the pallidum areas.) So, the areas discussed here are a small part of the entire brain, but interestingly clustered around the isthmus divider near the cerebellum.
Minimal viable straw man
I think it’s important to remember that the essay simulations are an engineering project not a scientific one. One difference is that the simulations necessary require decisions beyond science. Another difference is that the project needs a simple core that may not correspond to any evolutionary animal. For example, even simple animals have some rudimentary vision, if only two or three pigment spots. For another, learning centers like the mushroom body. And dealing with internal biological issues like breathing and blood pressure with motion.
This model in particular is more of a straw man or minimal viable product than an actual proposal for an ancestral proto-vertebrate mind. The model is intended to be a straw man, a target that might give a base framework to criticize or build on.
Alternative olfactory paths
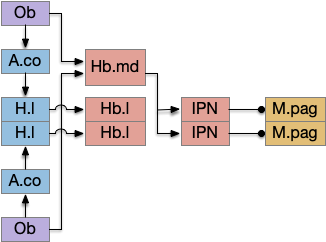
Another potential “what” path for innate behavior goes through the medial habenula, which is responsive to odors and produces place avoidance [Amo et al. 2014], but [Chen et al. 2019] suggests it also supports attraction for food odors.
Olfactory innate path through habenula. Key: A.co cortical amygdala, H.l lateral hypothalamus, Hb habenula (medial and lateral), IPN interpeduncular nucleus, M.pag periaqueductal gray, Ob olfactory bulb.
In mammals, the olfactory path to H.l goes through the cortical amygdala (A.co) [Cádiz-Moretti et al. 2017]. While this essay is deliberately omitting the cortex, in the lamprey the olfactory path goes through the lateral pallium (LPa, corresponding to mammalian O.pir piriform cortex) to the posterior tubercular (Snc in mammals.)
For this essay, I’ve picked the Ob to Snc path instead of the alternatives for simplicity. The habenula path is very tempting, but would require exploring the IPN and serotonin (5HT) paths to the MLR, which is more complicated than a “what” path through H.l
Subthalamic nucleus as give-up circuit
The sub thalamic nucleus (H.stn) is associated with a “stop” action, stopping downstream motor actions, either because of a new, surprising stimulus, or from higher-level commands. Since a give-up signal stops the seek goal, the stop action from H.stn might play a part in the control
H.stn stop is in parallel to habenular give-up. Key: H.l lateral hypothalamus, H.stn subthalamic nucleus, Hb.l lateral habenula, M.lr midbrain locomotor region, Snc substantia nigra pars compacta, Snr substantia nigra part reticulata.
H.stn is believed to have a role in patience in decision making [Frank 2006] and in encoding reward and cost [Zénon et al. 2016], which is very similar to the role of the habenula, and H.stn projects to Hb.l via P.hb habenula-projecting pallidum.
However, the H.stn’s patience is more related to holding off (stopping) action before making a decision, related to impulsiveness, while the give-up circuit is more related to persistence, continuing an action. So, while the two capabilities are related, they’re different functions. Since current essay simulation does not have patience-related behavior arrest but does need a give-up time, the habenula seems a better fit.
Serotonin inhibition path
In zebrafish, the habenula inhibits the dorsal raphe (V.dr, serotonin neurons) but not Snc or dopamine [Okamoto et al. 2021]. The inhibition works through V.dr to the Snc/posterior tubuculum to the locomotive regions.
As with the alternative olfactory paths, this serotonin inhibition path may be more evolutionary primitive, but would add complexity to the essay’s model, so will be held off for later exploration.
Conclusions
As mentioned above, the purpose of this model is a basis for the current essay’s simulation, and as a straw man to focus alternatives to see if there might be a better minimal model.
The essay 16 simulation is a foraging slug that follows odors to food, which must give-up on an odor when the odor plume doesn’t have food. Foraging researchers treat the give-up time as a measurable value, in optimal foraging in the context of the marginal value theorem (MVT), which tells when an animal should give up [Charnov 1976]. This post is a somewhat disorganized collection of issues related to implementing the internal state needed for give up time.
Giving up on an odor
The odor-following task finds food by following a promising odor. A naive implementation with a Braitenberg vehicle circuit [Braitenberg 1984], as early evolution might have tried, has the fatal flaw that the animal can’t give up on an odor. The circuit always approaches the odor.
Braitenberg vehicles for approach and avoid.
Since early evolution requires simplicity, a simple solution is adding a timer, possibly habituation but possibly a non-habituation timer. For example, a synapse LTD (long term depression) might ignore the sensor after some time. Or an explicit timer might trigger an inhibition state.
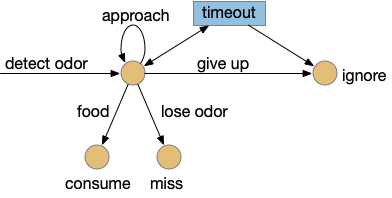
State diagram for the odor-following task with give-up timer. Blue is stateful; beige is stateless.
In the diagram, the beige nodes are stateless stimulus-response transitions. The blue area is internal state required to implement the timers. This post is loosely centered around exploring the state for give-up timing.
Fruit fly mushroom body neurons
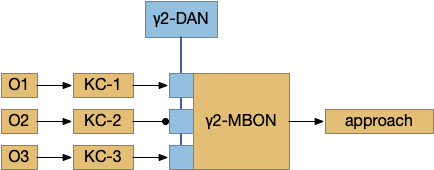
Consider a sub-circuit of the mushroom body, focusing on the Kenyon cell (KC) to mushroom body output neuron (MBON) synapses, and the dopamine neuron (DAN) that modulates it. For simplicity, I’m ignoring the KC fanout/fanin and ignoring the habituation layer between odor sensors and the KC, as if the animal was an ancestral Precambrian animal.
Give-up timing might be implemented either in the synapses in blue between the KC and MBON, or potentially in circuits feeding into the DAN. The blue synapses can depress over time (LTD) when receiving odor input [Berry et al. 2018], with a time interval on the order of 10-20 minutes. Alternatively, the timeout might occur in circuitry before the DAN and use dopamine to signal giving up.
In mammals, the second option involving a dopamine spike might signal a give-up time. Although the reward-prediction error (RPE) in the Vta (ventral tegmental area) is typically interpreted as a reinforcement-learning signal, it could also signal a give-up time.
Mammalian analogy
In mammals, a give-up signal might be a combination of some or all of several neurotransmitters: dopamine (DA), serotonin (5HT), acetylcholine (ACh), and possibly norepinephrine (NE).
Dopamine has a characteristic phasic dip when the animal decides no reward will come. Many researchers consider this no-reward dip to be a reward-prediction error (RPE) in the sense of reinforcement learning [Schultz 1997].
One of the many serotonin functions appears patience-related [Lottem et al. 2018], [Miyazaki et al. 2014]. Serotonin ramps while the animal is persevering at the task and rapidly drops when the animal gives. Serotonin is also required for reversal learning, although this may be unrelated.
Acetylcholine (ACh) is required for task switching. Since giving-up is a component of task switching, ACh likely plays some role in the circuit.
[Aston-Jones and Cohen 2005] suggest a related role for norepinephrine for patience, impatience and decision making.
On the one hand, having essentially all the important modulatory neurotransmitters involved in this problem doesn’t give a simple answer. On the other hand, the involvement of all of them in give-up timing may be an indication of how much neural circuitry is devoted to this problem.
Mammalian RPE circuitry
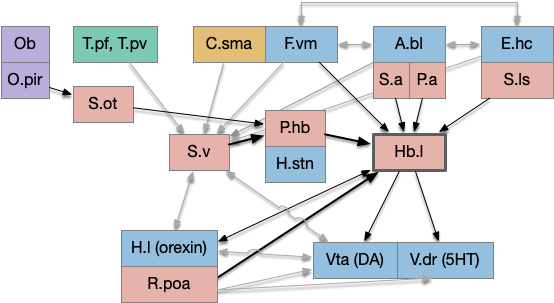
The following is a partial(!) diagram for the mammalian patience/failure learning circuit, assuming the RPE signal detected in DA/Vta is related to give-up time. The skeleton of the circuit is highly conserved: almost all of it exists in all vertebrates, with the possible exception ofr the cortical areas F.vm (ventromedial prefrontal cortex) and C.sma (supplemental motor area). For simplicity, the diagram doesn’t include the ACh (V.ldt/V.ppt) and NE (V.lc) circuits. The circuit’s center is the lateral habenula, which is associated with a non-reward failure signal.
Partial reward-error circuit in the mammalian brain.
Key: T.pf (parafascicular thalamus), T.pv (paraventricular thalamus), C.sma (supplementary motor area cortex), F.vm (ventromedial prefrontal cortex), A.bl (basolateral amygdala), E.hc (hippocampus), Ob (olfactory bulb), O.pir (piriform cortex), S.v (ventral striatum/nucleus accumbens), S.a (central amygdala), S.ls (lateral septum), S.ot (olfactory tubercle), P.hb (habenula-projecting pallidum), P.a (bed nucleus of the stria terminalis), Hb.l (lateral habenula), H.l (lateral hypothalamus), H.stn (sub thalamic nucleus), Poa (preoptic area), Vta (ventral tegmental area), V.dr (dorsal raphe), DA (dopamine), 5HT (serotonin). Blue – limbic, Red – striatal/pallidal. Beige – cortical. Green – thalamus.
Some observations, without going into too much detail. First, the hypothalamus and preoptic area is heavily involved in the circuit, which suggests its centrality and possibly primitive origin. Second, in mammals the patience/give-up circuit has access to many sophisticated timing and accumulator circuits, including C.sma, F.ofc (orbital frontal cortex), as well as value estimators like A.bl and context from episodic memory from E.hc (hippocampus.) This, essentially all of the limbic system projects to Hb.l (lateral habenula), a key node in the circuit.
Although the olfactory path (Ob to O.pir to S.ot to P.hb to Hb.l) is the most directly comparable to the fruit fly mushroom body, it’s almost certainly convergent evolution instead of a direct relation.
The most important point of this diagram is to show that mammalian give-up timing and RPE is so much more complex than the fruit fly, that results from mammalian studies don’t give much information for the fruit fly, although the reverse is certainly possible.
Reward prediction error (RPE)
Reward prediction error (RPE) itself is technically just an encoding of a reward result. A reward signal could either represent the reward directly or as a difference from a reference reward, for example the average reward. Computational reinforcement learning (RL) calls this signal RPE because RL is focused on the prediction not the signal. But an alternative perspective from the marginal value theorem (MVT) of foraging theory [Charnov 1976], suggests the animal use the RPE signal to decide when to give up.
The MVT suggests that an animal should give up on a patch when the current reward rate is lower than the average reward rate in the environment. If the RPE’s comparison reward is the average reward, then a positive RPE suggests the animal should stay in the current patch, and a negative RPE says the animal should consider giving up.
In mammals, [Montague et al. 1996] propose that RPE is used like computational reinforcement learning, specifically temporal difference (TD) learning, partly because they argue that TD can handle interval timing, which is related to the give up time that I need. However, TD’s timing representation requires a big increase in complexity.
Computational models
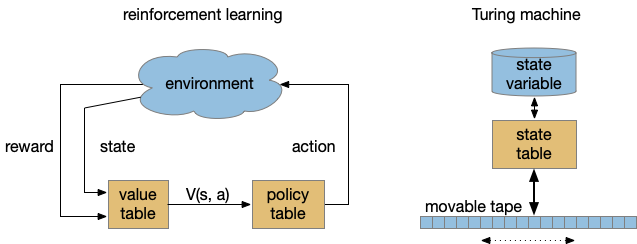
To see where the complexity of time comes from, let’s step back and consider computational models used by both RL and the Turing machine. While the Turing machine might seem to formal here, I think it’s useful to explore using a formal model for practical designs.
Reinforcement learning machine and Turning machine abstract diagram.
Both models above abstract the program into stateless transition tables. RL uses an intermediate value function followed by a policy table [Sutton and Barto 2018]. The Turing state is either in the current state variable (basically an integer) and the infinite tape. RL exports its entire state to the environment, making no distinction between internal state like a give-up timer and the external environment. Note the strong contrast with a neural model where every synapse can hold short-term or long-term state.
Unlike the Turing machine, the RL machine diagram is a simplification because researchers do explore beyond the static tabular model, such as using deep-learning representations for the functions. The TD algorithm itself doesn’t follow the model strictly because it updates the value and policy tables dynamically, which can create memory-like effects early in training.
The larger issue in this post’s topic is the representation of time. Both reinforcement learning and the Turing machine represent time as state transitions with a discrete ticking time clock. An interval timer or give-up timer is represented by states for each tick in the countdown.
State machine timeout
The give-up timeout is an illustration of the difference between neural circuits and state machines. In neural circuits, a single synapse can support a timeout using LTD (or STD) with biochemical processes decreasing synapse strength over time. In the fruit fly KC to MBON synapse, the timescale is on the order of minus (“interval” timing), but neural timers can implement many timescales from fractions of seconds to hours in a day (circadian).
State machines can implement timeouts as states and state transitions. Since state machines are clock based (tick-based), each transition occurs on a discrete, integral tick. For example, a timeout might look like the following diagram:
Portion of state machine for timeout.
This state isn’t a counter variable, it’s a tiny part of a state machine transition table. State machine complexity explodes with each added capability. If this timeout part of the state machine is 4 bits representing 9 states, and another mostly-independent part of the state machine has another 4 bits with 10 state, the total state machine would need 8 bits with 90-ish states, depending on the interactions between the two components because a state machine is one big table. So, while a Turing machine can theoretically implement any computation, in practice only relatively small state machines are usable.
Searle’s Chinese room
The tabular nature of state machines raises the philosophical thought experiment of Searle’s Chinese room, as an argument against computer understanding.
Searle’s Chinese room is a philosophical argument against any computational implementation of meaningful cognition. Searle imagines a person who doesn’t understand Chinese in a huge library with lookup books containing every response to every possible Chinese conversation. When the person receives a message, they find the corresponding phrase in one of the books and writes the proper response. So, the person in the Chinese room holds a conversation in Chinese without understanding a single word.
For clarity, the room’s lookup function is for the entire conversation until the last sentence, not just a sentence to sentence lookup. Essentially it’s like the input the attention/transformer deep learning as use in something like ChatGPT (with a difference that ChatGPT is non-tabular.) Because the input includes the conversational context, it can handle contextual continuity in the conversation.
The intuition behind the Chinese room is interesting because it’s an intuition against tabular state-transition systems like state machines, the Turing machine, and the reinforcement learning machine above. Searle’s intuition is basically since computer systems are all Turing computable, and Turing machines are tabular, but tabular lookup is an absurd notion of understanding Chinese (table intuition), therefore computers systems can never understand conversation. “The same arguments [Chinese room] would apply to … any Turing machine simulation of human mental processes.” [Searle 1980].
Temporal difference learning
TD learning can represent timeouts, as used in [Montague et al. 1996] to argue for TD as a model for the striatum, but this model doesn’t work at all for the fruit fly because each time step represents a new state, and therefore needs a new parameter for the value function. Since the fruit fly mushroom body only has 24 neurons, it’s implausible for each neuron to represent a new time step. Since the mammalian striatum is much larger (millions of neurons), it can encode many more values, but the low information rate from RPE (less than 1Hz), makes learning difficult.
These difficulties don’t mean TD is entirely wrong, or that some ideas from TD don’t apply to the striatum, but it does mean that a naive model of TD of the striatum might have trouble working at any significant scale.
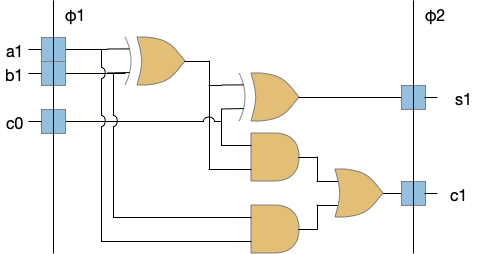
State in VLSI circuits
Although possibly a digression, I think it’s interesting to compare state in VLSI circuits (microprocessors) to both neurons, and the reinforcement learning machine and Turing machine. In some ways, state in VLSI resembles neurons more than it does formal computing models.
VLSI logic and state. Blue is state (latches) and beige is logic.
The φ1 and φ2 are clock signals needed together with the latch state to make the system work. The clocks and latches act like gates in an airlock or a water lock on a river. In a water lock only one gate is open at a time to prevent the water from rushing through. In the VLSI circuit, only one latch phase is active at a time to keep the logic bigs from mixing togethers. Some neuroscience proposals like [Hasselmo and Eichenbaum 2005] have a similar architecture for the hippocampus (E.hc) for similar reasons (keeping memory retrieval from mixing up memory encoding.)
In a synapse the slower signals like NMDA, plateau potentials, and modulating neurotransmitters and neuropeptides have latch-like properties because their activation is slower, integrative, and more stable compared to the fast neurotransmitters. In that sense, the slower transmission is a state element (or a memory element). If memory is a hierarchy of increasing durations, these slower signals are at the bottom, but they are nevertheless a form of memory.
The point of this digression is to illustrate that formal machine state models is unusual and possibly unnatural, even when describing electronic circuits. That’s not to say that those models are useless. In fact, they’re very helpful for mental models at the smaller scales, but in larger implementations, the complexity of the necessary state machines limits their value as an architectural model.
Conclusion
This post is mostly a collection of trying to understand why the RPE model bothers me as unworkable, not a complete argument. As mentioned above, I have no issues with a reward signal relative to a predicted reward, or using that differential signal for memory and learning. Both seem quite plausible. What doesn’t work for me is the jump to particular reinforcement learning models like temporal difference, adding external signals like SCS, and without taking into account the complexities and difficulties of truly implementing reinforcement learning. This post tries to explain some of the reasons for that skepticism.
While I was researching how the fruit fly might learn to ignore initially-attractive odors, I ran into a difficulty that most papers aren’t interested in that attractive-to-ignore transition. For this simulation this lack of information means I have needed to guess as to the plausibility. One possible reason for the lack of data might be an over-focus on specifics of classical associative learning.
Foraging and odor-following task
The task here is finding food by following a promising odor. As explored in the essay 15 and essay 16 simulations, this following-odor task is more complicated than it first appears because a naive solution leads to perseveration: never giving up on the odor. Perseveration is potentially fatal for the animal if it can’t break away from a non-rewarding lead, an inability to accept failure. To avoid this fatal flaw, there needs to be a specific circuit to handle that failure, otherwise the animal will follow the odor forever. At the same time, the animal must spend some time exploring the potential food area before giving up (patience). This dilemma is similar to the explore/exploit dilemma for foraging theory and reinforcement learning. A state diagram for the odor-foraging task might look something like the following:
Behavior state transitions for following an odor to food.
This odor task starts when the animal detects the odor. The animal approaches the odor repeatedly until it either finds food, the odor disappears, or the animal gives up. Giving up is the interesting case here because it requires an internal state transition, while all other inputs causes stimulus-reponse transitions: the animal just reacts. Finding food triggers consummation (eating), and disappearing odor voids the task. Both are external stimuli. In contract, giving up requires internal state circuitry to decide when to quit, a potentially difficult decision.
Learning to ignore
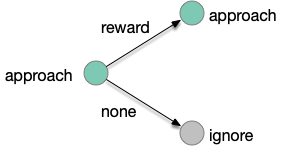
The animal can improve its odor-following performance if it can learn to ignore false leads, as explored in essay 15. The animal follows intrinsically-attractive odors and if there’s a reward it continues to approach the odor. But if the animal doesn’t find food, it remembers the odor and ignores the odor the next time. The simulations in essay 15 showed the effectiveness of this strategy, improving food discovery.
Learning transitions for an intrinsically attractive odor.
In the learning diagram above, when the animal finds food in an odor that predicts food, it maintains the intrinsic approach. When the animal doesn’t find food for that odor, it will ignore the odor for the next time. This learning is not simple habituation because the learning depends on the reward outcome, but it’s also not classical associative learning.
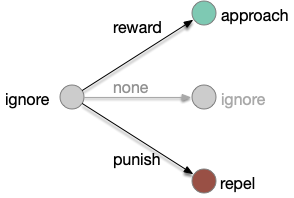
Classical associative learning
Classical associative learning (Pavlovian) starts from an initial blank state (tabula rasa) and learns from reward to approach and from punishment to avoid. The null transition, no reward and no punishment, maintains the initial blank state, although this assumption is implicit and not discussed as an important part of the model. A number of points about the classical associative learning model:
Learning transitions for classical associative learning, adding the implicit non-reward transition.
First, the greyed-out transition is an assumption, often untested or if it is tested, it’s dismissed as unimportant. For example, [Tempel et al. 1983] notes that OCT (a testing odor) becomes increasingly aversive even without punishment (a shock), which contradicts the greyed transition, but doesn’t incorporate that observation into the analysis. Similarly, [Berry et al. 2018] found that the test odors have increasing LTD (long-term depression) even without punishment or reward, but relegates that observation as unpublished data, presumably because it was irrelevant to the classical model in the study.
Second, classical association is a blank slate (tabula rasa) model: the initial state is an ignore state. Although fruit flies have intrinsically attractive odors and intrinsically repelling odors, research seems to focus on neutral odors. possibly because classical association expects an initial ignore state. But starting with neutral odors means there’s little data about learning with intrinsically attractive odors. For example attractive odors might be impervious to negative learning. In fruit flies, the lateral horn responds to non-learned behavior, such as intrinsic attractive odors. The mushroom body (learning) might not suppress the lateral horn’s intrinsic behavior for those odors.
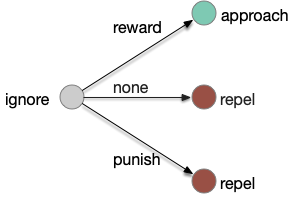
Learning transitions for a semi-classical situation where the non-reward transition learns aversion.
Third, in the fruit fly it’s unclear whether a no-reward transition uses the same MBONs as a punishment transition when the only negative learning data is from punishment studies. For example, both γ1-MBON and γ2-MBON are short term memory aversive-learning MBONs, as well as possibly α’3-MBON. A study that does test the no-reward transition as well as the punishment transition can distinguish between the two. [Hancock et al. 2022] includes a non-reward test to narrow the punishment effect to γ1, and notes non-reward depression for γ2, γ3, and γ4, but still treats and non-associative depression as outside the scope of interest.
Alternative learning model
An alternative is to treat all learning transitions as equally important, as opposed classical association’s focus on one a few transitions.
Alternative learning where all transitions are treated as interesting.
In the above diagram, seven of the nine transitions are interesting, and even the two trivial transitions, rewarded intrinsic-approach and punished intrinsic repel, are interesting in context of other transitions, because the implementing circuits might need to remember the reward.
Foraging learning revisited
Returning to the original foraging learning problem:
Learning transitions for an intrinsically-attractive odor.
How might this transition be implemented in the fruit fly mushroom body? A single-neuron implementation might be possible if a reward can reverse a habituation-like LTD for the none transition, such as a dopamine spike leading to LTP (long-term potentiation). A dual-neuron implementation might use one neuron to store the reward vs non-reward state and the other to store a visited-recently data, such as the surprise neuron α’3 [Hattori et al. 2017].