While I was researching how the fruit fly might learn to ignore initially-attractive odors, I ran into a difficulty that most papers aren’t interested in that attractive-to-ignore transition. For this simulation this lack of information means I have needed to guess as to the plausibility. One possible reason for the lack of data might be an over-focus on specifics of classical associative learning.
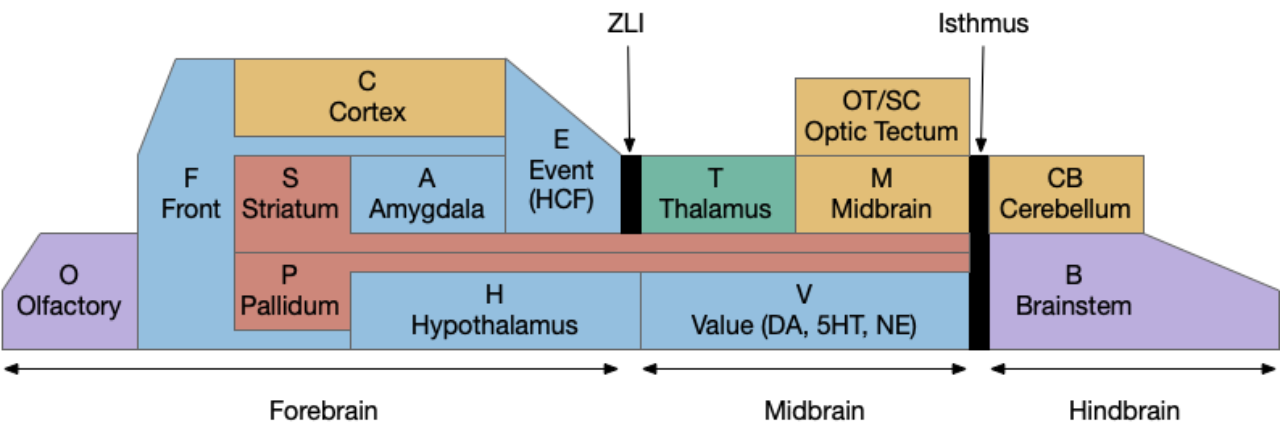
Foraging and odor-following task
The task here is finding food by following a promising odor. As explored in the essay 15 and essay 16 simulations, this following-odor task is more complicated than it first appears because a naive solution leads to perseveration: never giving up on the odor. Perseveration is potentially fatal for the animal if it can’t break away from a non-rewarding lead, an inability to accept failure. To avoid this fatal flaw, there needs to be a specific circuit to handle that failure, otherwise the animal will follow the odor forever. At the same time, the animal must spend some time exploring the potential food area before giving up (patience). This dilemma is similar to the explore/exploit dilemma for foraging theory and reinforcement learning. A state diagram for the odor-foraging task might look something like the following:
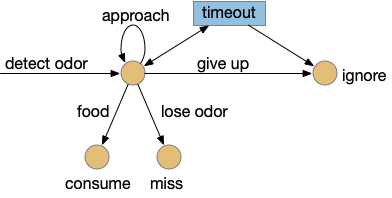
This odor task starts when the animal detects the odor. The animal approaches the odor repeatedly until it either finds food, the odor disappears, or the animal gives up. Giving up is the interesting case here because it requires an internal state transition, while all other inputs causes stimulus-reponse transitions: the animal just reacts. Finding food triggers consummation (eating), and disappearing odor voids the task. Both are external stimuli. In contract, giving up requires internal state circuitry to decide when to quit, a potentially difficult decision.
Learning to ignore
The animal can improve its odor-following performance if it can learn to ignore false leads, as explored in essay 15. The animal follows intrinsically-attractive odors and if there’s a reward it continues to approach the odor. But if the animal doesn’t find food, it remembers the odor and ignores the odor the next time. The simulations in essay 15 showed the effectiveness of this strategy, improving food discovery.
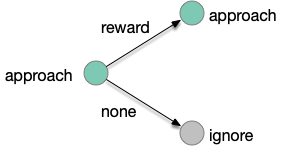
In the learning diagram above, when the animal finds food in an odor that predicts food, it maintains the intrinsic approach. When the animal doesn’t find food for that odor, it will ignore the odor for the next time. This learning is not simple habituation because the learning depends on the reward outcome, but it’s also not classical associative learning.
Classical associative learning
Classical associative learning (Pavlovian) starts from an initial blank state (tabula rasa) and learns from reward to approach and from punishment to avoid. The null transition, no reward and no punishment, maintains the initial blank state, although this assumption is implicit and not discussed as an important part of the model. A number of points about the classical associative learning model:
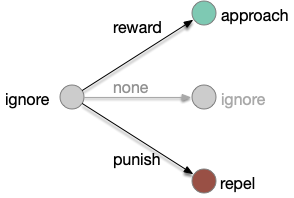
First, the greyed-out transition is an assumption, often untested or if it is tested, it’s dismissed as unimportant. For example, [Tempel et al. 1983] notes that OCT (a testing odor) becomes increasingly aversive even without punishment (a shock), which contradicts the greyed transition, but doesn’t incorporate that observation into the analysis. Similarly, [Berry et al. 2018] found that the test odors have increasing LTD (long-term depression) even without punishment or reward, but relegates that observation as unpublished data, presumably because it was irrelevant to the classical model in the study.
Second, classical association is a blank slate (tabula rasa) model: the initial state is an ignore state. Although fruit flies have intrinsically attractive odors and intrinsically repelling odors, research seems to focus on neutral odors. possibly because classical association expects an initial ignore state. But starting with neutral odors means there’s little data about learning with intrinsically attractive odors. For example attractive odors might be impervious to negative learning. In fruit flies, the lateral horn responds to non-learned behavior, such as intrinsic attractive odors. The mushroom body (learning) might not suppress the lateral horn’s intrinsic behavior for those odors.
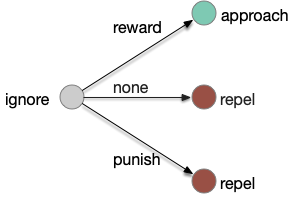
Third, in the fruit fly it’s unclear whether a no-reward transition uses the same MBONs as a punishment transition when the only negative learning data is from punishment studies. For example, both γ1-MBON and γ2-MBON are short term memory aversive-learning MBONs, as well as possibly α’3-MBON. A study that does test the no-reward transition as well as the punishment transition can distinguish between the two. [Hancock et al. 2022] includes a non-reward test to narrow the punishment effect to γ1, and notes non-reward depression for γ2, γ3, and γ4, but still treats and non-associative depression as outside the scope of interest.
Alternative learning model
An alternative is to treat all learning transitions as equally important, as opposed classical association’s focus on one a few transitions.
In the above diagram, seven of the nine transitions are interesting, and even the two trivial transitions, rewarded intrinsic-approach and punished intrinsic repel, are interesting in context of other transitions, because the implementing circuits might need to remember the reward.
Foraging learning revisited
Returning to the original foraging learning problem:
How might this transition be implemented in the fruit fly mushroom body? A single-neuron implementation might be possible if a reward can reverse a habituation-like LTD for the none transition, such as a dopamine spike leading to LTP (long-term potentiation). A dual-neuron implementation might use one neuron to store the reward vs non-reward state and the other to store a visited-recently data, such as the surprise neuron α’3 [Hattori et al. 2017].
References
Berry JA, Phan A, Davis RL. Dopamine Neurons Mediate Learning and Forgetting through Bidirectional Modulation of a Memory Trace. Cell Rep. 2018 Oct 16
Hancock, C.E., Rostami, V., Rachad, E.Y. et al. Visualization of learning-induced synaptic plasticity in output neurons of the Drosophila mushroom body γ-lobe. Sci Rep 12, 10421 (2022).
Hattori, Daisuke, et al. Representations of novelty and familiarity in a mushroom body compartment. Cell 169.5 (2017): 956-969.
Tempel, Bruce L., et al. Reward learning in normal and mutant Drosophila. Proceedings of the National Academy of Sciences 80.5 (1983): 1482-1486.