The feeding essay introduced a number of issues both uncovered by the simulation and problems with the neuroscience. The simulation emphasized issues with the timing of the dwell state, where dwelling at the wrong time can inhibit search. Another issue as a bug was getting stuck switching states where roaming didn’t restart. The biggest neuroscience problem is a possible/likely massive misinterpretation of H.pstn (presubthalamic nucleus).
Dwell timing
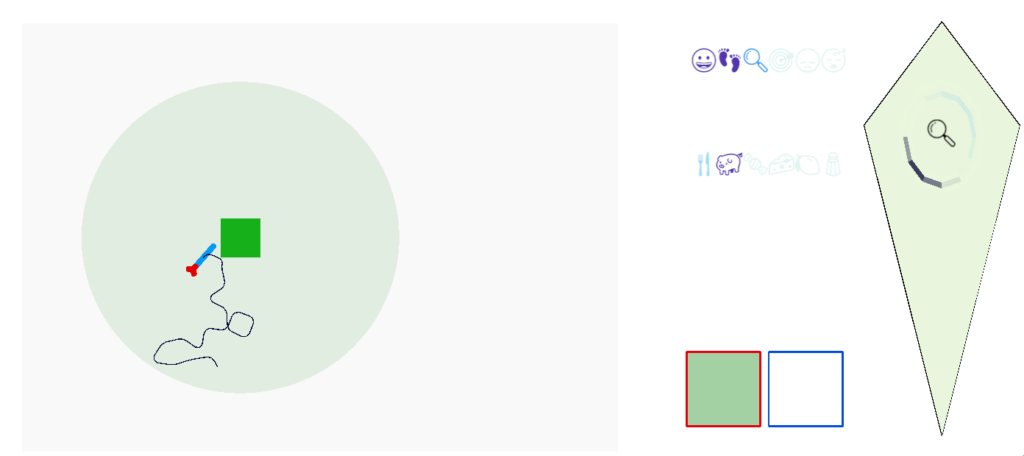
The initial trigger for a dwell state varies between species [Dorfman et al 2020]. The simulation quickly showed why. In the current simulation, since food is a single item in the center of an odor plume, dwell could either trigger on entering the odor plume or after eating food.
Simulation where the animal dwells when entering the odor plume.
As the screenshot shows, the dwell search is counterproductive because it’s too far from the food. When dwell triggers from eating, like ladybugs eating aphids [Dorfman et al 2020], the area restricted search is more effective.
Getting stuck in a state
One programming bug happened after the animal ate, leaving the eating state, but it didn’t start the roaming state, instead remaining stuck. The roaming state didn’t recover after the eating state.
Which raises a question about a state machine model, which I’m already skeptical about as a good model of the mind. In programming, state machines can be useful because the states and transitions are enumerable, which makes them testable, because humans are good at working through lists and cases. But evolution can’t work through a list of cases, and neural circuits are not well suited to complicated mutually-exclusive state transitions.
For example, imagine a neural state machine, and consider when evolution adds a new state or a new state transition? In theory, it needs to update all the circuits for the other states to consider the new cases for the new state and new transition. Since state machines are combinatorial, each new state or transition increases complexity based on the current complexity of the state machine. Adding a state or transition to a 2-state machine is relatively simple, but adding a state or transition to a 10-state machine is much more complicated. In programming, you can work through all the new combinations and handle each case, but evolution would require new mutations for each case. It’s not impossible but becomes less likely as complexity arises.
H.pstn as misinterpreted in the essay
Essay 27 used a hypothetical H.pstn (presubthalamic nucleus) as the eating analog to H.stn (subthalamic nucleus), where each can pause actions to manage state transitions. That model treated H.pstn and H.stn as parallel modules laterally inhibiting each other. But H.pstn research has mostly found H.pstn as an inhibitory module, pausing eating for external threads or for sickness or bitterness, not as a driving force [Barbier et al 2020].
But it’s possible that H.pstn research may be preliminary, and other regions had also found negative, aversive functions to areas that later were found to have mixed function, including H.stn itself [Watson et al 2021]. Early research had assigned negative “fear”, freezing, or stopping behavior to entire regions like H.stn, M.pag.vl (periaqueductal gray, ventral-lateral), and S.a (central amygdala), but later research found a more varied behavior. These areas only appeared to be negative because a small sub-area implemented avoidance or freezing [La-Vu et al 2020]. So, it’s possible that H.pstn might have non-avoidant function, but it seems more likely that H.pstn is not an exact parallel to H.stn for eating.
H.stn is topographically ordered by motor areas and includes mouth and facial motor areas. If H.stn does perform a sustain and transition function, it might sustain and transition many/most motor areas, without a specific carve-out for feeding.
Eating-triggered dwell vs reward
A behaviorist might describe the essay, as saying that dwell is triggered by reward. I’ve been deliberately avoiding using the term reward for eating, for several reasons including those given by [Salamone and Correa 2012]. Two reasons are that the essays don’t yet have reinforcement and the meaning of “reward” is highly tied to reinforcement. A second is that reward implicitly assumes a common currency for valence, but the implementation of a common currency requires circuitry to create that currency.
Another reason raised by this essay is that eating-triggered behavior does not necessarily follow the behaviorist reward model, and specifically this essay’s eating-dependent behavior isn’t associative learning.
Suppose I use “reward-triggered dwell” instead of “eating-triggered dwell.” First, the term would be incorrect because the simulation doesn’t have an erased-source common currency “reward”. It specifically triggers from eating. Second, “reward” implies that there’s either a hedonic component (“liking”), which the simulation doesn’t have, or a motivational component, which is more complicated, because the “dwell” state is motivational.
The model required a major refactoring to properly simulate the essay.
Model update to simulate essay 27.
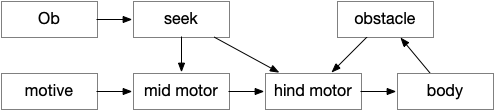
HindMotor
HindMotor includes the motor command areas in the hind-brain with locomotion and eating as separate modules. Locomotion models B.rs (reticulospinal motor command neurons) and B.mdd (medulla reticular neurons). Eating models parts of B.pb (parabrachial nucleus), B.nts (nucleus of the solitary tract) and B.mdd. The locomotion and eating modules do not coordinate at the hind-brain level for this model.
In this essay, HindMotor controls the random search, modulated by upstream request, and also manages action bouts. One an action starts, it continues until complete, which generally requires several simulation ticks. Because the essay model is real-time, not turn-based, actions require several simulation ticks to complete.
HindMotor locomotion commands are split between directional hints and forward movement hints, following a similar division in vertebrates. Turn modulation comes from target seeking and obstacle avoidance, either encouraging or inhibiting left vs right turns. Forward movement modulation comes from the motive core, specifically selecting between a roaming search or an area-restricted dwelling search.
MidMotor
MidMotor coordinates actions that HindMotor implements. MidMotor with sustains actions across action bouts, and manages the transition between action bouts. Because ongoing movement needs to stop before eating, MidMotor pauses eating until the animal stops.
MidMotor represents Ppt (predunculopontine nucleus), H.stn (subthalamic nucleus), OT.d (deep optic tectum), MLR (midbrain locomotor region), and T.pf (parafascicular nucleus). For this essay, Ppt and H.stn work together as a single module to sustain actions and pause upcoming actions until currently-active actions are complete.
Seek
The essay Seek is directional movement toward a specific target, the same idea as taxis (but avoiding Greek). Seek is only active with a specific directional cue, here an olfactory gradient.
Seek models Hb.m (medial habenula) and M.ip (interpeduncular nucleus), where M.ip is models as a gradient seek module like the Drosophila fan-shaped body.
CoreMotive
CoreMotive simulates the motivational core, which is primarily peptide based. In this essay, the neural areas include H.l (lateral hypothalamus), V.dr (dorsal raphe), and B.pb (parabrachial nucleus). H.l is strongly associated with all aspects of feeding and is the driving controller. V.dr expresses the dwell state, which restricts search to a small area once the animal has found food. B.pb manages eating, taste, and physical alarms that might interrupt eating.
Motive neuropeptides
Because the motive core is more broadcast neuropeptide-based than a connective circuit, the simulation includes broadcast neuropeptides as primitive motives. In this essay, the key motives are Roam (motivation to search for food, orexin), Dwell (area restricted search, serotonin), Seek (tracking a target, dopamine) and Sated (antagonizing all food search, GLP-1).
Each motive is a DecayValue, which represents a slow leaky integrator, where the decay time can be tens of seconds or longer, because neuropeptide timing can be long. To a Dwell signal might last for 20 seconds or more without requiring recurrent neural behavior to maintain the state. Since these Motives are broadcast, they can modulate any module with requiring a direct connection.
Screenshot after eating, showing multiple active motives.
The screenshot above shows several motives after the animal eats, where emojis represent the active motives. The animal is sated (pid), eating is fading (faded fork and knife), search is in dwell (magnifying glass) because the animal has just eaten, and it’s still roaming (footprints).
Essay 27 returns to feeding, which essay 23 had an earlier sketch of. While the animal in earlier essays could eat while moving, like snails and worms, this essay will add the requirement of stopping before eating, which requires extra control mechanisms to manage the state transition.
A filter feeder like amphioxus, a non-vertebrate chordate that may hint at pre-vertebrate feeding, might move to find a better feeding zone, but then settles down as a static filter feeder. Tunicates, which are more closely related to vertebrates settle down permanently as adults and dissolve their brain as no longer needed. Because I want to keep the essay simple, I’m imaging something more like licking, which is more studied in rodents, as opposed to a more alien filter feeding. The main problem for the essay to introduce locomotion and eating as distinct actions.
As a contrast to further explore the idea of states and state transitions, the essays also explores the transition between roaming and dwelling: global wide-ranging search vs area restricted search. Roaming and dwelling are more amorphous motivational states as opposed to the strict motor division between moving and eating.
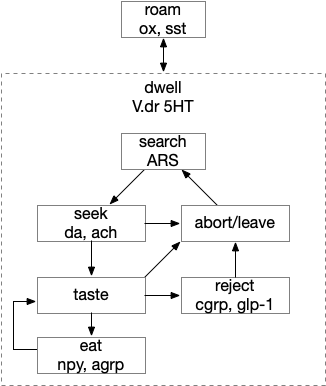
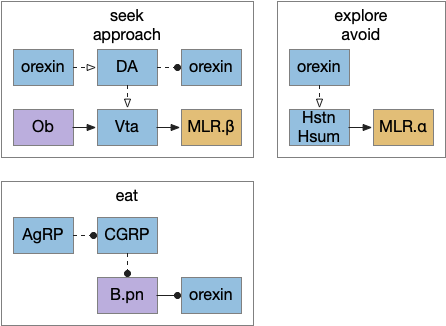
Feeding states
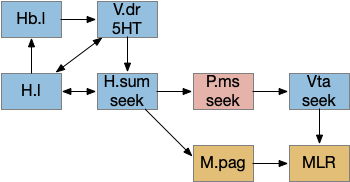
Below is a more detailed diagram of the foraging and feeding states, revolving around the core foraging task. The animal passively roams until is finds an odor cue for a food target, which starts a seek to the target. If it finds food, the animal sops and eats.
In this model, the roam state and dwell state can be separate from seeking a target, depending on the animal’s environmental niche. A seek can start in a roam state or a dwell state, and seek cues may or may not initiate dwell state. For example, dwell state might only start when the animal eats nutritious food, indicating that food is nearby.
Feeding state diagram for the essay. ach (acetylcholine neurotransmitter) agrp (hunger peptide), ARS (area restricted search), cgrp (alarm/bitter taste peptide), da (dopamine), glp-1 (satiety/sickness peptide), ox (orexin wakefulness/action peptide), set (somatostatin peptide), V.dr (dorsal raphe), 5HT (serotonin)
The diagram includes important failure states. If seeking fails, the animal gives up and leaves the area, and must ignore the last cue to avoid perseveration. If the taste is bitter or toxic, the animal rejects the food. For now, I’m postponing longer failure states like the food lacking nutritional value or causing food poisoning.
To avoid perseveration, seeking the failed cue forever, the avoid state moves the animal away from the failed cue and ignores seek cues. A more sophisticated brain could remember the failed cue for a short time, but the current essays lack short term memory.
Eating here means specifically licking or filter feeding. I’m being precise here because the simulation requires it, and more vague neuroscience terms like “reward” are often unclear about exactly what it’s relation to actual eating are.
The connection between the dwell state and serotonin is from [Flavell et al 2013], [Ji et al 2021] which founds serotonin marking the dwell state in the flatworm C. elegans, and [Marques et al 2020] finding serotonin for a zebrafish dwell (“exploit”) state.
Roaming and dwelling
Food search phases have multiple strategies, broadly divided into roaming and dwelling. Roaming is a broader, more general search without a specific area or target. Dwelling or ARS (area restricted search) is slower, with tighter turning, where the current area is believed to be more likely to have food. [Horstick et al 2017] describes dwell as four properties: reduction in travel distance, increased change in orientation, increased path complexity, and a directional bias.
For this essay, dwelling is a motivational drive not a motor command, meaning it can overlap with other motivations and doesn’t provide a strict action state requirement. For example, dwell isn’t required to seek a target, which can occur in the roaming state, for example in C. elegans [Ji et al 2021].
In the C. elegans the dwell state is associated with serotonin and the roam state with PDF (pigment dispensing factor) [Flavell et al 2013]. In zebrafish the dwell state is associated with V.dr (dorsal raphe) serotonin [Marques et al 2020], the roam state is associated with SST (somatostatin peptide) [Horstick et al 2017]. While arousal isn’t quite the same as well, [Lovett-Barron et al 2017] found SST as a low-arousal marker, while CART, ACh (acetylcholine), NE (norepinephrine), serotonin, dopamine and NPY (neuropeptide Y) as signs of high arousal.
Triggers for the dwell state depend on the animal’s species [Dorfman et al 2020]. In C. elegans, which feeds on bacteria, nutritional feedback extends the dwell state [Ben Arous et al 2009]. In some animals a food cue triggers dwell, while in others only eating nutritious food triggers dwell. In zebrafish lack of a food cue causes H.c (caudal hypothalamus) activation decay [Wee et al 2019].
Reflexive eating
This essay models reflexive eating as a hindbrain system controlled by B.pb (parabrachial nucleus) with downstream motor and sensory in B.nts (nuclei tractus solitarius), M.mdd (reticular medulla), and B.3g (trigeminal – orofacial sensorimotor). The simulation isn’t as detailed, treating the hindbrain eating as a single low-level module.
This innate circuit can with without input from higher areas [Watts et al 2022]. For example if rodents lack any dopamine, they won’t move or eat and will starve even if food is near them. However, if food or water is placed at their lips, which activates the innate circuit, the rodents will eat [Rossi et al 2016].
The B.pb area also processes sweet, bitter or salt, and can reject food without requiring higher areas. The higher areas modulate B.pb behavior, such as suppressing B.pb’s innate rejection of sour when drinking lemonade.
Because the B.pb innate eating and the MLR (midbrain locomotor region) are independent, some system much coordinate switching between moving and eating.
The illusion of state machine atomicity
The feeding state diagram suggests a simple atomic transition from seeking food to eating the food, but this transition needs management from some neural circuits. For example, when braking during driving, drivers need to pay attention to the stopping distance. Braking stops a car, but the state transition isn’t a simple atomic transition. For this essay’s eating task, some neural circuit must keep track of the animal’s stopping after seeking and only allow eating when locomotion has stopped.
State transition from seeking to eating, emphasizing the stopping state. H.pstn (parasubthalamic nucleus), H.stn (subthalamic nucleus).
H.stn (subthalamic nucleus) is involved with stopping, waiting, and switching tasks [Isoda and Hikosaka 2008]. Since H.stn also receives motor efference copies via T.pf (thalamus parafascicular nucleus) and Ppt (peduncular pontine nucleus), H.stn is in a good position to manage the stopping transition and can prevent eating until the locomotion has ended. The diagrams shows H.pstn (parasubthalamic nucleus) as a parallel area for gaiting eating, following [Barbier et al 2021].
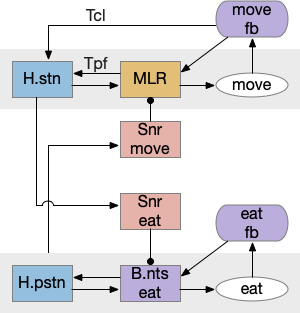
H.stn and H.pstn state transition circuit
H.stn and H.pstn are well-placed to fulfill the transitions between seeking and eating. To flesh this idea out, here’s a simplified model of the seal to eat state transition circuit.
The main action paths are horizontal: moving is from H.stn to MLR to B.rs (reticulospinal motor neurons) and eating is from H.pstn to B.nts to orofacial licking motor neurons. The rest of the circuit manages the transition between the two states.
State transition circuit for move state to eat state. B.nts (nucleus tractus solidarus), fb (feedback), H.pstn (parasubthalamic nucleus), H.stn (subthalamic nucleus), MLR (midbrain locomotor region), Snr (substantia nigra pars reticulata), T.cl (centrolateral thalamus), T.pf (parafascicular thalamus).
Control over the transition comes from S.nr (substantia nigra pars reticulata), which inhibits eating when the animal is moving, and inhibits moving while the animal is eating. To know when the animal has stopped moving, H.stn receives motor efferent copies from T.cl and T.pf (centrolateral and parafascicular thalamus, aka intralaminar). As a note, T.cl contains cerebellum output, so H.stn may receive fine-grained motor timing feedback. H.pstn receives parallel eating efferent copies from B.pb and B.nts to know when the animal has stopped eating.
This circuit has the same structure as a lateral inhibition decision circuit, but the function is about handling timing and transition, not deciding between competing options.
Note: [Shah et al 2022] suggest H.pstn is more specific to suppressing feeding for aversive situations like food poisoning or a predator threat, but not the motor control as described here.
A note on this model: the actual neural circuit isn’t as clean, parallel and logical, because evolution isn’t an intelligent designer. Furthermore, this brain region is part of the neuropeptide core, where neuropeptide broadcast-like signaling can be more important than point-to-point circuit diagrams. Specifically, the disinhibition of B.pb eating is more likely peptides from the hypothalamus, not S.nr tonic inhibition.
H.l food zone
Studies on H.l (lateral hypothalamus) show two interesting results relevant here [Jennings et al 2015]:
Two distinct GABA neuron populations gate eating and seeking.
Two distinct neuron populations are active in a food zone or outside a food zone.
The food zone neurons partially explain how H.l decides between seeking and eating. How does this animal knows when it’s reached the food? In C. elegans there are dopamine chemosensory neurons that sense when the animal passes over food bacteria, and signals the animal to slow [Sawin et al 2000]. Dopamine chemosensory neurons also signal for the animal to turn more when leaving food (dwell-like state) [Hills et al 2004]. For this essay, using B.pb and B.nts to sense nearby food seems like a reasonable simplification because the simulation animal is aquatic and aquatic taste is a chemosensory system, similar to a close-range olfaction.
Food zone modulation of seeking and eating. fz (food zone), H.l (lateral hypothalamus).
The essay uses a signal when the animal is in a food zone or not in a food zone. The food zone signal inhibits eating or seeking actions when the animal is in a non-appropriate place. The essay uses a signal from B.pb as mentioned above.
In mammals H.l receives input from more sophisticated location systems than a bare chemosensory signal, such as E.sub.d (dorsal subiculum of hippocampus), S.ls (lateral septum, which processes hippocampal output), A.bl (basolateral amygdala, highly connected to hippocampus), S.msh (medial shell striatum receiving large hippocampus input) as well as the bare B.pb as for the simulation. All these areas incorporate more complicated environmental context. When the essays start investigating environmental context, I’ll need to revisit the H.l food zone with more sophisticated input.
H.sum as driving seek
Fleshing out the drivers of the seek circuit, consider H.sum (supramammillary nucleus, aka retromammillary) and its role in exploring (roaming and seeking). [Ferrell et al 2021] study a subset of H.sum neurons that express tac1 peptide (tachykinin, aka substance-P or neurokinin). These H.sum neurons correlate highly with movement velocity, a second before the action. Since they precede action, they’re upstream in the locomotive path.
H.sum also participates in threat avoidance [Escobedo et al 2023], but that circuit is through Poa (preoptic area) and is outside this essay, although it would be interesting if any of the downstream circuitry is shared. H.sum is also well know for its role in hippocampal theta oscillations, novelty [Chen et al 2020], temporal and spatial memory [Cui et al 2013], and social memory, although those are outside the scope of this essay.
The diagram below shows a possible explore-related path of mammalian H.sum via the tac1 neurons.
It may be important that H.sum and Vta (ventral tegmental area) are both neighbors and H.sum includes dopamine neurons and those dopamine neurons are sometimes considered an extension of the Vta [Yetnikoff et al 2014].
The following diagram gives an extremely rough idea of the adjacency of these areas. In a smaller primitive pre-vertebrate, these might not only be neighbors but mingled earlier functionality. The diagram includes H.zi (zona incerta) because it’s a neighbor, and also because H.zi is a food-seeking area [Ye et al 2023], but I’m postponing consideration of H.zi to a future essay.
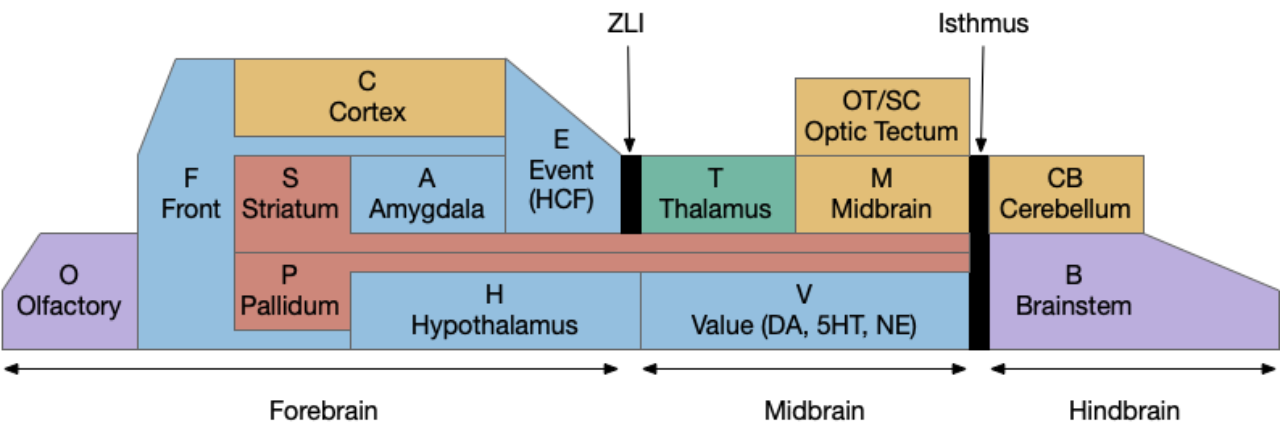
Neighbors of the lateral habenula and supramammillary nucleus. H.l (lateral hypothalamus), H.pstn (parasubthalamic nucleus), H.stn (subthalamic nucleus), H.sum (supramammillary nucleus), H.zi (zona incerta), MLR (midbrain locomotive region), Ppt (Pedunculopontine pontine nucleus), Snc (substantia nigra pars compacta – dopamine), Snr (substantia nigra pars reticulata), Vta (ventral tegmental nucleus – dopamine), ZLI (zona limitans intrathalamica).
In addition, the rostral part of Vta nearest H.sum is part of p3 in the prosomeric embryonic model, which is a source of hypothalamic cells [Kim et al 2022]. For pre-vertebrates in this essay, then, there might not be a distinct between H.sum and Vta / posterior tuberculum, particularly since the essays are currently focusing on downstream connections, not upstream dopamine to a future striatum. Zebrafish downstream dopamine circuits directly modulate locomotor movement [Ryczko et al 2020], [Reinig et al 2017]. I think it’s reasonable to simplify this circuit for now and consider H.sum as directly projecting to MLR.
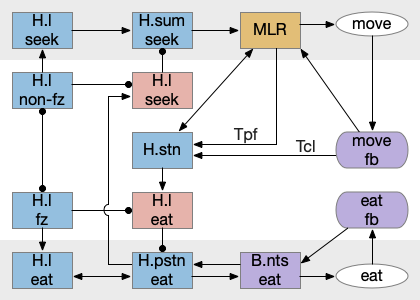
State transition circuit for seek to eat
Putting these ideas together yields something like the diagram below. Like the earlier simplified diagram, horizontal paths drive core seeking and eating behavior, and other circuits manage the state transition. Seeking uses the top path from H.l to H.sum to MLR to B.rs, which produces the final locomotion. Eating uses the bottom path from H.l to H.pstn to B.nts, which controls reflexive eating.
The left contains motivational drivers. The food zone and non food zone systems restrict seeking and eating, only allowing seeking and eating in appropriate locations.
In the center H.stn and its parallel H.stn enforce a smooth transition between seeking and eating, using motor efferent copies to pause transition until active motor stops. The smooth transition creates the illusion of an atomic state transition.
As a diagram note, I’ve used red for the H.l inhibitory neurons that gate seek and eat because they’re playing the same role as Snr neurons. Technically they should be blue, if following normal essay conventions.
Modulation of eating
The eating and feeding modulation systems are complicated and overlapping, which is too detailed for this essay, but two part are interesting. First, B.pb tonically inhibits eating with the CGRP peptide to B.nts. To enable eating, H.arc (hypothalamus arcuate) disinhibits B.nts eating by sending AgRP (a hunger peptide) to B.pb [Campos et al 2016].
Modulation of reflexive eating. AgRP (a hunger peptide), B.nts (nucleus of the solitary tract), B.pb (parabrachial nucleus), CGRP (an anti-eating peptide), H.arc (hypothalamus arcuate).
Although the essays have used the disinhibition pattern before, the pattern has generally ben GABA disinhibition, while this feeding disinhibition uses peptide signaling. As mentioned above, there are many feeding-related peptides that inhibit, excite, and modulate the feeding system without using connection based synapses.
As a parallel, a drinking modulation path goes through the basal ganglia Snr and OT (optic tectum) [Rossi et al 2016]. This path though the basal ganglia and OT coordinates anticipatory licking, while the earlier B.nts path is reflexive eating.
Control of anticipatory licking. B.mdd (medulla licking motor), OT.dl (deep, lateral optic tectum), Snr.l (lateral substantia nigra pars reticulata)
Another drinking path involves S.a (central/striatal amygdala), midbrain, and hindbrain circuits [Zheng et al 2022]. M.dp (deep mesencephalic nucleus) extends licking but doesn’t initiate it. So M.dp might extend eating after tasting. Similarly B.plc extends eating [Gong et al 2020]. S.a sst (somatostatin peptide) neurons promote eating and drinking [Kim et al 2017].
Sustained eating with an amygdala circuit. B.mdd (medulla motor eating), B.pb (parabrachial nucleus), M.dp (deep mesencephalic nucleus), S.a.sst (set-expressing neurons of the central amygdala).
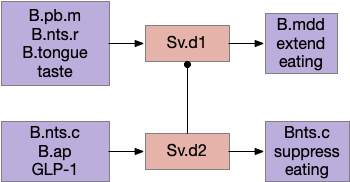
Another path for tasting and eating runs through S.v (ventral striatum). [Sandoval-Rodríguez et al 2023] founds S.v directly controlling feeding using hindbrain taste input to extend eating, and using hindbrain GLP-1 (anti-eating peptide) to inhibit eating. Unlike most striatum circuits, these striatum neurons project directly to the hindbrain motor areas.
Ventral striatum taste exciting and food inhibition circuit with the hindbrain. B.ap (area postrema – nutrient sensing), B.mdd (medulla motor), B.nts (nucleus of the solitary tract), B.pb (parabrachial nucleus), Sv (ventral striatum / nucleus accumbens).
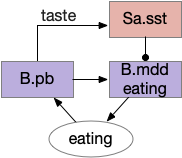
Because this essay is already complicated enough, this simulation isn’t covering all of these details. For simplicity, the simulation will use a simple continuation circuit inspired by the central amygdala and postpone other control circuits for later exploration.
Simplified eating continuation circuit with the central amygdala. B.mdd (medulla motor), B.pb (parabrachial nucleus), Sa.sst (central amygdala, sst projecting neurons)
The important point for now is that eating modulation uses multiple paths, some controlled through synaptic circuits and others through broadcast motivational peptides. The system is not one or the other, but a messy combination. To model this messiness, the simulation needs to handle both systems.
Chen S, He L, Huang AJY, Boehringer R, Robert V, Wintzer ME, Polygalov D, Weitemier AZ, Tao Y, Gu M, Middleton SJ, Namiki K, Hama H, Therreau L, Chevaleyre V, Hioki H, Miyawaki A, Piskorowski RA, McHugh TJ. A hypothalamic novelty signal modulates hippocampal memory. Nature. 2020
Farrell JS, Lovett-Barron M, Klein PM, Sparks FT, Gschwind T, Ortiz AL, Ahanonu B, Bradbury S, Terada S, Oijala M, Hwaun E, Dudok B, Szabo G, Schnitzer MJ, Deisseroth K, Losonczy A, Soltesz I. Supramammillary regulation of locomotion and hippocampal activity. Science. 2021 Dec 17;374(6574):1492-1496.
Unsurprisingly since essay 26 was a first cut at selective attention, it exposed a number of problems with both the neuroscience and the simulation model itself.
Specific give up
The current give up circuit is a global circuit, which doesn’t depend on the current stimulus. For this essay, the animal has two potential and because the give up is global, when the animal gives up, it gives up on both odors.
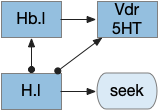
Global give-up circuit for olfactory seek. H.l lateral hypothalamus, Hb.l lateral habenula, Vdr dorsal raphe, 5HT serotonin.
An improvement would be a cue-specific give up capability. When the animal gives up on odor A, it should investigate odor B. Instead it gives up on both. I need to add some mechanism to create a cue-specific give up capability.
As a possible neural analog, the adenosine receptor can work as a local give-up circuit by integrating neural activity. Since adenosine is essentially a waste produce from neural activity, long activity will accumulate adenosine. The A1 adenosine receptor detects the adenosine and inhibits activity, since it’s a Gi receptor.
Olfactory complexity and attention
The essay’s odor model is extremely oversimplified, because odor receptors are feature detectors, not molecule receptors, and odors are combinations of molecules. Since a specific odor is a combination of features, P.bf (basal forebrain) can’t be a simple winner-take-all inhibitory circuit as implemented in this essay. Instead, attention needs to be a set of features that excludes the distractor odor’s features.
Olfactory gamma and beta
Although the essay treats the olfactory bulb data as direct signals, oscillations are a major feature of the olfactory bulb. Strong odors trigger gamma (40-100Hz) signals in Omt (mitral/tufted output cells), enhanced by ACh (acetylcholine) from P.bf. Feedback from O.pir (olfactory piriform cortex) triggers beta (15-30Hz) oscillations. In addition, interactions with breathing in mammals synchronized with theta (4-10Hz). Although, in the last case, since the simulation animal is aquatic, breathing isn’t an appropriate synchronizer.
Temporal gradient seek issues
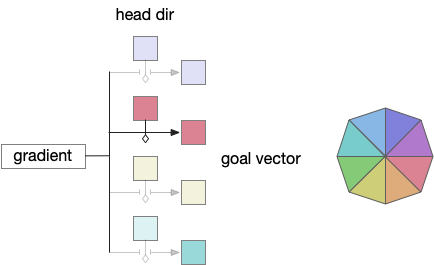
Odor seeking in essay 26 uses temporal gradient descent modulated by head direction in Hb.m (medial habenula) and B.ip (interpeduncular nucleus). The animal combines its head direction with the temporal gradient to estimate the odor direction, and it saves the result as a goal vector. As the animal turns, it can improve the direct estimate. In the phototaxis example of essay 25, the saved goal vector direction helped with intermittent data, where it could remember the light location for a few seconds.
Problems with the current odor direction. A quick switch in location incorporates data from the old direction, leading to an incorrect estimate.
However, the system as implemented in the model is extremely limited. It can’t truly triangulate to locate the odor, but can only improve the single direction. In the diagram above, the animal can only select one of the two vectors as an estimate. It can’t combine the two into a better estimate of the center. Also, in the diagram, the earlier estimate is no longer useful because the animal has moved.
Now, the issue might be purely in the simulation. If B.ip and Vdr (dorsal raphe serotonin) are calculating this kind of estimate, it’s likely their computation is better than the current simulation.
The selection is a trade off where a stronger gradient is likely a better estimate, but if the animal moves too far from the earlier sample, the old direction is no longer relevant. Since the animal lacks the sophistication of an allocentric map to resolve the discrepancy, it discards the old value.
The current implementation decays the old estimate to allow newer estimates to overwrite it even if the later gradient is weaker. Essentially the memory is like a leaky integrator, as is appropriate for placing it in the serotonin neurons and/or associate glia with short term (5s) memory as in simple zebrafish motor memory [Dragomir et al 2020].
Bayesian updates
In a future essay, it might be interesting to explore this issue to see if a simple Bayesian system could be implemented in low-complexity circuits, where stronger data would update the current model more than the current model.
Self motion and gradient vectors
When the animal is turning, the running average no longer represents a straight line. For the gradient vector, the system assumes the recent average was measured along the current head direction, but turns violate this assumption. To avoid miscalculating gradient vectors, the animal should suppress measurement during turns.
Swimming and theta
The gradient seek issues above are compounded with swimming with a fixed head. Early vertebrates would have had a fixed head like sharks, meaning that each swimming stroke would move the head from side to side. That sideways movement would affect the odor gradient and head direction.
Inconsistent head vs body direction and odor measurement while swimming with a fixed head.
A simplistic fix would take an odor gradient sample only on each swim stroke, only reporting at the stroke end for consistency and to average from the beginning of the stroke to the end. That solution would give a consistent measurement in a reasonably consistent direction, as opposed to sampling randomly in a cycle.
Log encoding vs linear encoding
For simplicity, I’e used linear encoding for signals in the essays, because the basic functional architecture remains the same, and the simulation isn’t precise enough to need more complexity. But for odors, the dynamic range between a single molecule detection and an overpowering odor doesn’t scale well with a linear representation.
In particular, the odor weight from the simple distance gradient, together with above mentioned temporal gradient issues might be better modeled with a log signal. Basically, the issue I raised above with gradient vector sampling might be more tractable with a different encoding, and log encoding might make the actual neural circuit less finicky than the current linear model.
Seek mode switching
The essay’s simulation lacks a specific mode switching circuit. In vertebrates the peptide core (hypothalamus, PAG, B.pb area) switches action modes from roaming to seek to eating to rest and sleep. These modes are motivated and depend on internal needs and scheduling impulses programmed by evolution.
I’ve been ignoring distracting cues in the previous essays for simplification. Since the simulated animal only encountered a single odor at a time, it never needed to select one and ignore the other. In essay 26, I’ll implement a very simple first approximation to ignoring distractors, using the P.bf (basal forebrain) control of the Ob (olfactory bulb) as a switchboard to let the selected odor through and inhibit the ignored distractor.
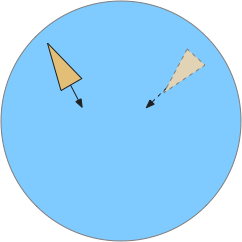
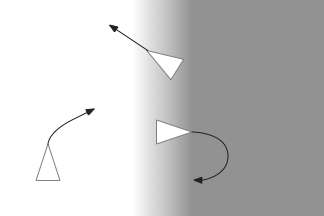
Simulated animal (triangle) encountering two odor plumes (circles).
In the diagram above, the animal (triangle) is seeking food using the purple odor cue as a gradient direction. When it encounters the distractor odor in blue, it should ignore the distractor, otherwise the two odors will mingle into an incorrect summed gradient and the animal will seek in the wrong direction [Cisek 2022].
Temporal chemotaxis
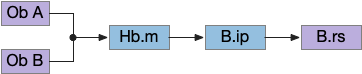
For essay 26, I’m switching chemotaxis (odor seeking) to use the apical temporal gradient search, using Hb.m (medial habenula) and B.ip (interpeduncular nucleus) like the phototaxis in essay 24. The apical system follows the chimera brain model of [Tosches and Arendt 2013], which suggests that odor senses and actions are distinct systems from bilateral tactile senses. For the essays, the shift is from a bilateral, Braitenberg-like [Braitenberg 1984] system to a modulated random walk like the bacterial tumble-and-run.
Olfactory tumble-and-run system using Hb.m and B.ip for temporal gradient direction, and B.rs for the modulated random walk. B.ip interpeduncular nucleus, B.rs hindbrain reticulospinal motor area, Hb.m medial habenula, Ob olfactory bulb.
The above diagram shows the problem with distractor odors. Because the tumble-and-run system uses a single temporal gradient, it necessarily adds both odors together for its input. The summed input goes to the Hb.m (medial habenula) and B.ip (interpeduncular nucleus) system to modulate the random walk direction.
When the animal crosses into the overlapping distractor odor, it will follow the combined signal, distracted from the original seek target. To avoid distraction, the system can either amplify the current odor A, or inhibit the distractors like odor B.
Analogy with nucleus isthmi
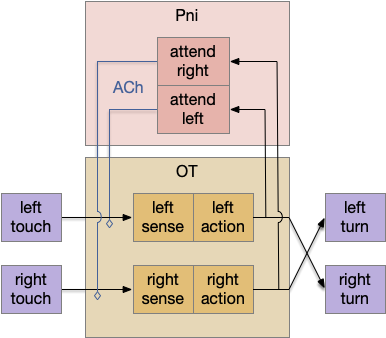
An earlier essay 19 also had an attention / distractor problem, with a different issue of action consistency, and used a zebrafish circuit in P.ni (nucleus isthmi) as a solution. In larval zebrafish P.ni works together with OT (optic tectum) to sustain attention on prey during a hunt [Henriques et al 2019]. P.ni is an ACh (acetylcholine neurotransmitter) and GABA (inhibiting neurotransmitter) system that both amplifies the predicted prey location and inhibits surrounding areas.
Nucleus isthmi circuit as adapted by essay 19. ACh acetylcholine, OT optic tectum, Pni nucleus isthmi.
In the above diagram for the essay 19 circuit, a simultaneous left and right touch would select one action at random and sustain that choice for subsequent movement with the P.ni positive feedback circuit. The outputs are crossed because it’s an avoidance circuit: an obstacle on the left triggers a right turn.
Importantly, the positive feedback is modulatory; it doesn’t trigger an action by itself. At a synapse level, ACh triggers mAChR (ACh metabotropic receptor, Gs stimulatory type) on the sensor axon, amplifying the sensor’s neurotransmitter release. The ACh and mAChR act as the decay timer, because they have a slow time constant on the order of a few seconds. If the sensor doesn’t stimulate the circuit, as when successfully avoiding the obstacle, the attention will decay over a few seconds, resetting the system to its original state.
A similar function applies to Ob and P.bf (basal forebrain), where P.bf acts like P.ni to sustain attention to the selected odor. “Basal forebrain” is a general name for a collection of functionally-related subcortical areas in the ventral (“basal”) forebrain, all pallidal-like (P). The specific P areas for the Ob are P.hdb (horizontal diagonal band) and Po.me (magnocellular preoptic area), but I’ll use P.bf for simplicity.
Olfactory bulb as a switchboard
In this model, Ob acts like a switchboard controlled by P.bf. P.bf selects attended odor paths in Ob, where Ob either passes the odor signal to its destination or inhibits the signal if it’s a distractor. P.bf opens and closes gated circuits in Ob.
Although the architecture of the Ob and P.bf circuit resembles the P.ni circuit, Ob appears to rely more heavily on inhibitory GABA for the gating operation, although ACh is also important [Böhm et al 2020], [de Saint Jan et al 2020], [Nunez-Parra et al 2000]. Since this essay is a first cut, simplified model, I’m using a single signal that represents a gating attention / inhibition signal, and glossing over the ACh vs GABA distinction.
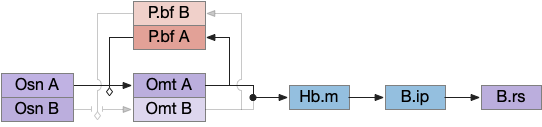
Olfactory bulb switchboard using basal forebrain to gate selected odors. B.ip interpeduncular nucleus, B.rs reticulospinal motor, Hb.m medial habenula, Omt mitral/tufted output cells, Osn olfactory sensor neurons, P.bf basal forebrain.
In the above diagram where the switchboard selects odor A and inhibits odor B, the apical seek circuit receives only odor A’s signal. P.bf gates odors from Osn (olfactory sensory neurons) to Omt (mitral/tufted output cells), which then add to form a single signal for the temporal gradient tumble-and-run seek. For simplicity, I’ve shown the P.bf ACh and GABA signal as a simple gating control.
Once the system detects odor A, P.bf configures the switchboard to pass through A and inhibit other odors, locking out the distractor. Because the selecting signals are modulators, they don’t drive a signal until an odor signal arrives. Like the P.ni circuit, attention will timeout as ACh and its slow mACh receptor decay. When the animal leaves the odor plume, the system resets because the absence of odor A collapses the feedback loop.
Although the essay’s switchboard is an improvement over the naive summation of odor signals, it’s still quite limited. There’s no active selection of a best odor, and the system can’t switch to a better odor cue. Also, since the global give-up circuit isn’t integrated with P.bf, giving up on odor A can’t select odor B. Instead the animal must leave the plume and reset the system.
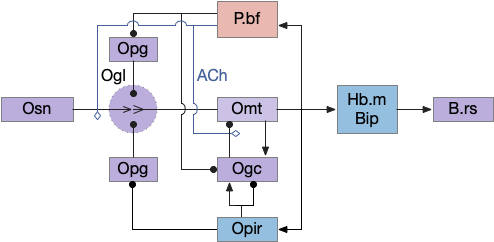
Slightly more complete Ob switchboard
The Ob is a surprisingly complex system; it’s not just a simple odor system. In addition to the P.bf, Opir (olfactory piriform cortex) also modulates the Ob system, and Ob itself has lateral inhibition between Omt (mitral cell output), which is plastic, learning to discriminate odors itself, as well as modulatory input from the serotonin and noradrenaline system.
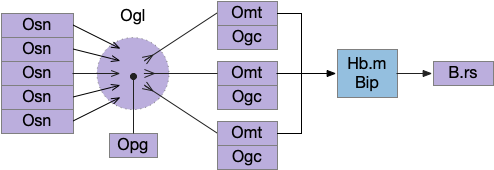
In the real Ob, many Osn for the same odor feed into a single Ogl (olfactory glomeruli), which provides input to several Omt, all representing the same odor. Each odor feature has its own Ogl system, several hundred in mammals (two in the essay simulation). Ogl is where the neuropil of the Osn axons meet the Omt dendrites, in a fan-in to fan-out system. Also, each Ogl has many inhibitory Opg (periglomerular inhibitors) with multiple variations, and each Omt has several inhibitory Ogc (olfactory granule cells). The basic fan-in and fan-out structure looks like the following diagram.
To break down the diagram, the core of the switchboard circuit is the Osn to Ogl to Omt to output path; everything else is gating to select or inhibit the signal.
Odor gating happens in two locations: modulating Omt’s input dendrite tree in Ogl by Opg and modulating Omt’s output by Ogc (olfactory granular cell). Because each Omt’s input Ogl is shared for several Omt, the Opg inhibition likely affects many or all Omt for a single Ogl. In contrast, the Ogc inhibition is individual, and the Omt and Ogc circuit creates and manages gamma oscillations, which amplifies and reduces noise from the signal.
Although I’m not planning on touching cortical areas for many essays, the Opir (olfactory piriform cortex) modules the Ob switchboard in a similar circuit as B.pf with some difference. Since the Opir input to the many Ogc and many Ogl is not odor selective [Boyd et al 2015], Ogc must learn the meaning of the Opir input through plasticity.
Global give-up circuit
The essay’s task engagement and give-up circuit currently uses H.l (lateral hypothalamus) and Hb.l (lateral habenula) with V.dr (dorsal raphe serotonin) [Hikosaka 2010], [Chowdhury and Yamanaka 2016]. When a seek fails Hb.l suppresses H.l, H.l ends seek, and the animal moves on [Post et al 2022].
Because the global give-up circuit is entirely disconnected from the olfactory selective attention from the essay, giving up means giving up on all odors, not just the current attended odor.
Simulation
For this essay, I refactored much of the simulation code to clean up ideas from previous essays. A new hindbrain module manages the main locomotion like the zebrafish hindbrain motor area [Dunn et al 2016], which is possibly different from the tetrapod / amniote locomotion in the midbrain. Because the essay animal is currently more primitive than amniotes, this simplification seemed appropriate and makes the code organization more clear.
Olfactory locomotion is now random-walk based following apical tumble-and-run, as opposed to the earlier bilateral path through Vta (ventral tegmental area / posterior tuberculum) and OT (tectum). In zebrafish both paths exist, which I might explore later, but this essay is restricted to the apical temporal gradient search.
The seek mode now slows the animal and adjusts the Levy walk parameters to simulate ARS (area restricted search). As I’ll cover in the problems section, switching to seek mode is still hardcoded.
I split the habenula seek from habenula give-up (Hb.m from Hb.l) and pulled the gradient seek and head direction from B.ip into the habenula seek. Conceptually, the habenula seek code now represents Hb.m and B.ip as a single complex.
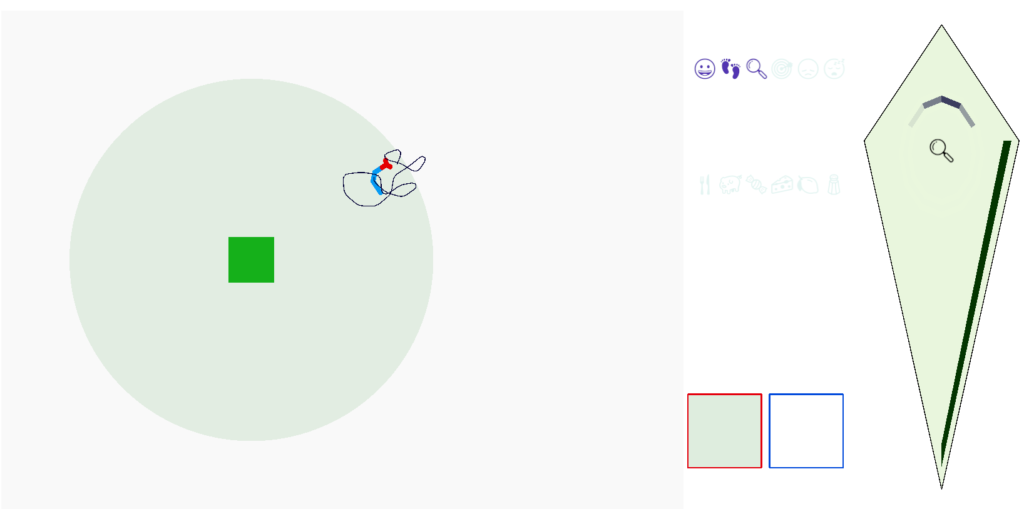
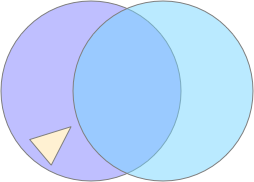
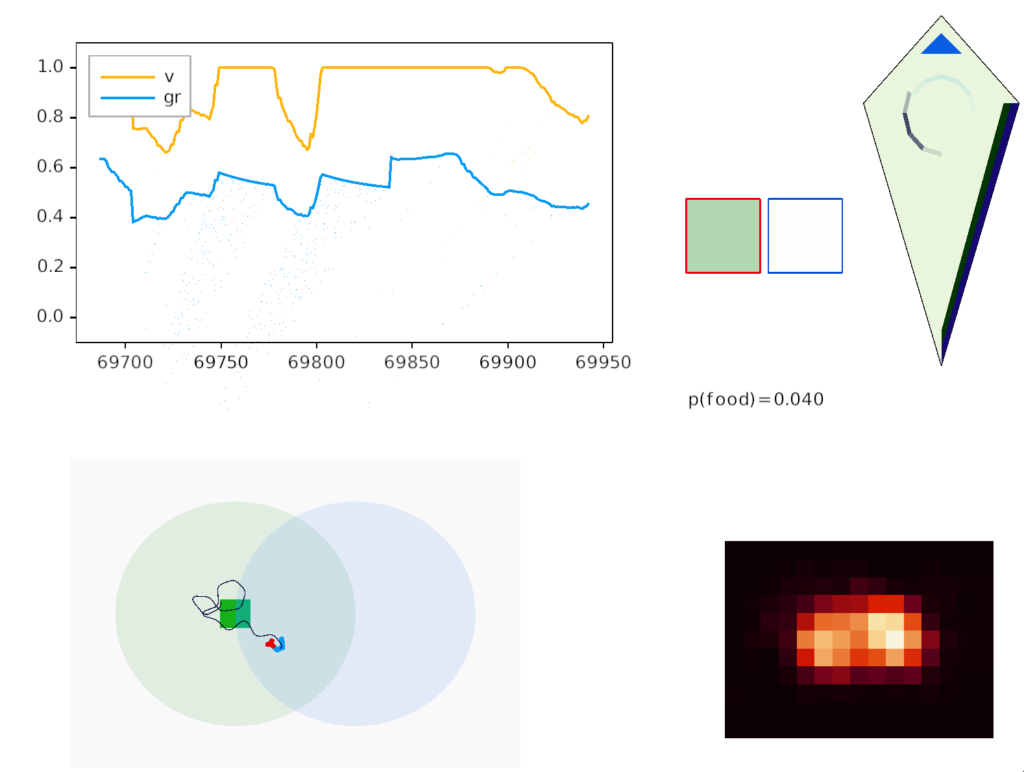
Simulated odor seeking with target attention and distractor inhibition.
In the screenshot above, the animal is making a u-turn to return to the food when the odor gradient (blue semicircle) is opposite the head direction (black semicircle). In the upper right, the green box outlined in red represents the attended green odor signal, while the white box outline in blue represents the suppressed blue odor. Despite the Osn naively sensing both blue and green odors because the animal is in the overlap area, only the green odor passes through Omt to the seek system.
The square borders around the odor color represent P.bf modulation. Red is attended (100% pass through), blue is inhibited (10% pass through), and grey is unmodulated (50% pass through).
In the diamond-shaped homunculus, the bright blue triangle represents the u-turn nudge.
As the goal vector shows, the guessed goal direction isn’t very accurate, particularly when the animal is making a turn. Currently, the animal continues to update its guess even in the middle of a turn when the odor data and averages are not appropriate for the current direction.
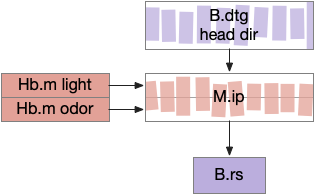
Essay 24, which investigated temporal gradient navigation, raised the question of head direction and navigation. The essay 24 model followed a zebrafish phototaxis experiment by [Chen and Engert 2014] which created a virtual light spot surrounded by darkness. The phototaxis behavior used Hb.m (medial habenula) and B.ip (interpeduncular nucleus) path using 5HT (serotonin) from V.mr (median raphe) as an average integrator [Cheng et al 2016] to generate the gradient without using head direction. Since B.ip receives head direction input [Petrucco et al 2023], essay 25 explores using head direction with the phototaxis gradient.
In the fruit fly drosophila, head direction and goal direction combine in the fan-shaped body to produce motor commands toward the goal [Matheson et al 2022]. Since the vertebrate B.ip connectivity with head direction resembles the fan-shaped body, this essay will use it as a model.
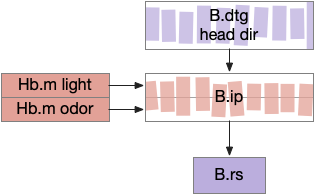
B.ip connectivity
Head direction from B.dtg (dorsal tegmental nucleus of Gudden) and the photo-gradient input from Hb.m would combine in tabular rows and columns in B.ip, if it resembles the fan-shaped body.
B.ip connectivity following a fan-shaped body model. B.dtg dorsal tegmental nucleus of Gudden, B.ip interpeduncular nucleus, B.rs reticulospinal motor command, Hb.m medial habenula.
Head direction encoding
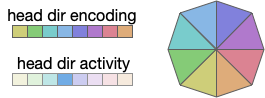
Head direction is necessarily encoded by neurons. Each neuron in the head direction population has a specific direction, and fires when the animal is heading toward the neuron’s preferred direction.
Head direction encoding. Each neuron (colored box) corresponds to a direction. The neuron in the current direction is active, while other directions are silent.
In general, the heading is encoded is an ensemble of neurons, where several neurons around the actual direction fire at different rates (or possibly delayed phases). In the diagram above, the central direction (blue) has a higher activity while neighboring neurons have smaller values [Petrucco et al 2023].
Drosophila uses a coding for its head direction, where the amplitude of the actual direction neuron is close to one and the neurons at orthogonal directions are zero [Westeinde et al 2022]. This sinusoidal encoding enables neuron-friendly transformations and combinations [Touretzky et al 1993] with advantages over neural rate-encoding or phase encoding, particularly in response speed.
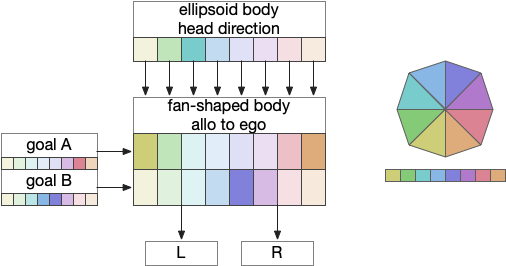
Fan-shaped body: allocentric to egocentric
Fruit fly navigation uses its fly-shaped body to combine an allocentric goal direction with the head direction to create motor commands to turn left or right. Egocentric is self-focused and allocentric is other-focused. Allocentric coordinates are animal-independent like North or toward a distant landmark, which egocentric coordinates are relative to the animal, like forward, right or left.
The fan-shaped body has a tabular shape where each column is a head direction and each row is a goal input [Hulse et al 2021]. The fan-shaped body combines the goal vector and the head direction to create motor commands [Westeinde et al 2022].
The fan-shaped body combines head direction with goal vectors to produce motor commands.
By shifting the head direction and combining the sinusoidal encodings of the goal vector, the motor output is a turn toward left or right. In drosophila, there’s a third motor command for a U-turn when the goal is behind the fly. Each motor command is carried by a specific neuron: PFL2.L (left), PFL2.R (right), and PFL3 (U-turn).
In drosophila, there are 18 distinct head direction columns and up to 9 goal rows. The fan-shaped body is also used for motivation calculations like sleep, despite sleep not fitting into the strict tabular model shown above. To create the strict organization, the fan-shaped body has 400 distinct neuron types [Hulse et al 2021].
Constructing goal vectors
In the phototaxis situation as in essay 24 or [Chen and Engert 2014] the goal vector is constructed from the gradient as the animal enters darkness from light and the head direction at that moment.
Captured goal vector (red) when the animal crosses into darkness.
As the diagram above suggests, the stored vector isn’t the true direction from light to dark, but only the sample along the animal’s path. The gradient value is then stored in the goal direction cells.
Storing the goal vector requires gating based on head direction. In zebrafish, serotonin accumulators can be gated by actions and used as a short term memory (5s – 20s) [Kawashima et al 2016]. For the essay, head dir gates serotonin accumulation as a replacement for the action gating.
Storing gradient into the goal vector based on the current goal. The red direction (south-east) gates its associated serotonin accumulator.
Since V.mr (median raphe) neurons produce consistent tonic oscillations, they are ideal for reading the accumulated value. No additional circuitry for the read is necessary.
Essay simulation
Because the essay model is a functional level, not a circuit level, it can use a directional vector encoding: a pair of floating-point numbers for direction and gradient for strength.
The simulation also calculated two averages: a short-term average for the goal vector gradient and a long-term average for phototaxis gradient motivation. The goal vector average needs to be shorter to avoid bleed-over from a previous direction.
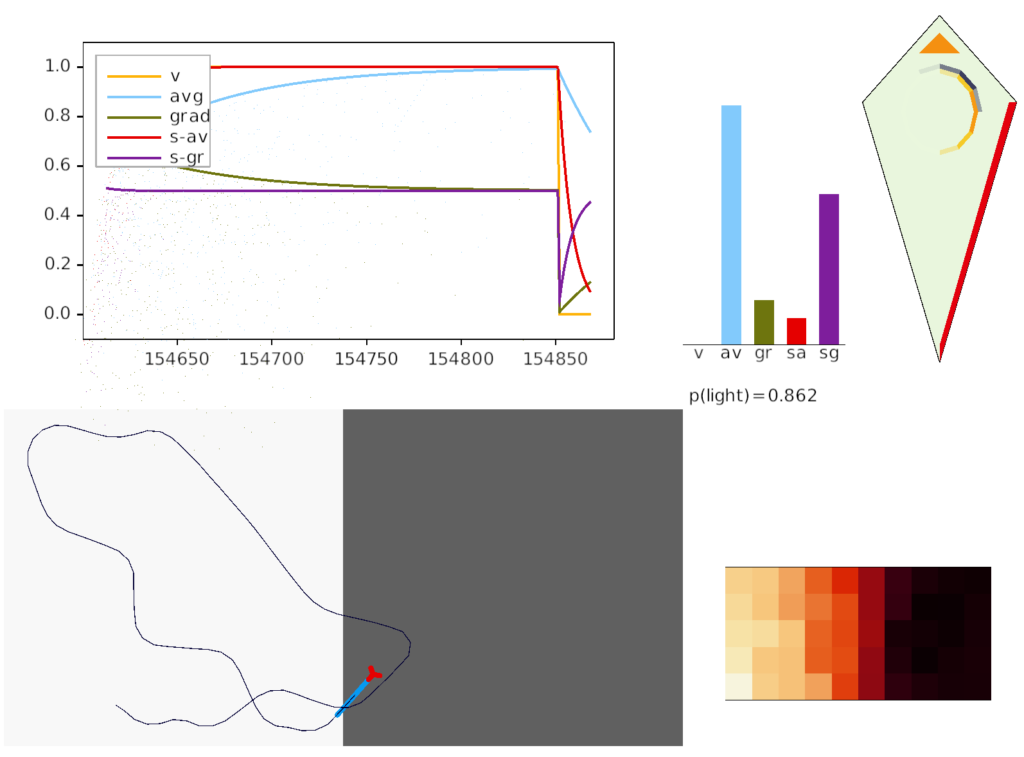
Screenshot of animal crossing into darkness.
The above screenshot shows the animal’s state when it crosses into darkness. The long-timescale motivational gradient (“gr/grad”) is negative, driving the animal to avoid darkness. The short directional gradient (“sa”) is near zero, avoiding update of the stored goal vector. (Note: gradients are 0.5-centered for graphing consistency.)
The homunculus diamond in the upper right shows the current head direction (black semicircle pointing north-east) and the avoidance goal vector (orange semi-circle pointing east). Since the animal is heading toward the avoidance direction, it has a U-turn motor command (orange triangle at top). In addition, since the goal vector and head direction are near a right angle, right turns are inhibited (red at lower right). Because locomotion remains exploratory and stochastic, inhibits reduce turn probability but don’t force turns.
Discussion
This essay’s model is more speculative even compared to other essays, because I haven’t found any papers reporting in B.ip head direction behavior other than the base existence of head direction afferents [Petrucco et al 2023]. In particular, the drosophila fan-shaped body is not homologous to B.ip because the pre-vertebrate animal amphioxus lacks either structure. Nevertheless, it’s interesting that a goal gradient vector circuit is at least possible and relatively simple.
Specifically, the goal vector provides an evolutionary step toward hippocampal (E.hc) object vector cells and grid cells, because those are relatively small enhancements over the goal vector. Without a Bi.ip goal vector system as an intermediary step, hippocampal navigation is too big of an evolutionary step with too many concurrent requirements to be likely.
Note that the hippocampal system is strongly connected with the Hb, B.ip, V.mr, B.dtg system from this essay. E.hc (hippocampus), P.ms (medial septum), Hb (habenula), B.ip (interpeuncular nucleus), V.mr (median raphe), B.dtg (head direction) form a strong connected system together with H.sum (supramammilary/ retromammilary nucleus).
The simple phototaxis implementation exposes a few problem with the simulation, both from running it and from reviewing neuroscience to critique it.
Interrupts
The essay doesn’t currently implement any interrupt mechanism. When running into darkness, the animal turns around and starts an area restricted search (ARS), but if the animal is in the middle of a long Levy path, it will cross the border and the search will not find the border.
Long initial paths breaks the phototaxis algorithm.
The problem here is that the ARS starts too late because the animal doesn’t interrupt the current behavior when encountering the border.
One solution is to create an interrupt (orientation) system, which exists in the vertebrate brain in V.ppt (peduncular pontine nucleus), and uses ACh (acetylcholine) to interrupt the current behavior. A natural location for the interrupt is V.ppt for the signal and the stratum as the plan representation, interruptible via ACh interrupts to the striatum.
Another solution is to avoid the uninterruptible behavior entirely, where the problem is the essay’s Levy walk implementation. The essay pre-computes the length of a run instead of continuously creating extensions. In contrast the zebrafish larva swims in bouts, but longer runs are made of multiple forward bouts.
Zebrafish random walk (ARTR area)
The essay’s random walk does not match actual zebrafish search behavior. The essay uses a turn-and-run model where the turn and run length are computed randomly. The zebrafish has a hindbrain oscillator, the ARTR (anterior rhombencephalic turning region) which selects left and right turns [Karpenko et al 2020].
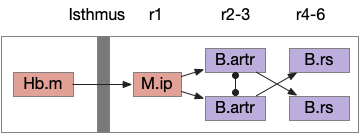
Speculative directed random walk with the zebrafish ARTR. The isthmus is the midbrain-hindbrain boundary (MHB). B.artr anterior rhombencephalic turning region, B.rs reticulospinal motor command, Hb.m medial habenula, M.ip interpeduncular nucleus.
In zebrafish, turns and runs are selected independently and can be chained differently. Instead of turn-run-turn-run as in the essay, the zebrafish can have turn-turn or run-run patters. Zebrafish turn direction is also correlated, as opposed to the random walk’s turn independence. A zebrafish left turn is more likely to follow a left turn.
When encountering darkness, the same-direction turns increase. When encountering light, alternating turns increase. Together with the sharp turn (O-bend) followed b shallower turns, this behavior should create a spiral-like search for the light area.
Note: this specialized circuitry in the hindbrain suggests that random search is a primitive behavior. Although the essay put the Levy walk logic in the midbrain, it belongs in the more primitive hindbrain.
Head direction
[Petrucco et al 2023] report that M.ip is highly connected with head direction axons from B.dtg (dorsal tegmental area of Gudden). This head direction does not receive vestibular input, but is likely derived from motor efferent copies. Since both M.ip and B.dtg are r1-derived regions and possibly ante-vestibular, this head-direction and M.ip connection may be ancient.
Speculative M.ip circuit following the fruit fly fan-shaped body. B.dtg dorsal tegmental nucleus of Gudde, B.rs reticulospinal motor command, Hb.m medial habenula, M.ip interpeduncular nucleus.
This organization is strikingly similar to the fruit fly’s ellipsoid body (EB), protocerebral bridge (PB), and fan-shaped body (FB) in the central complex (CX) [Hulse et al 2021]. EB and PB calculate head direction. The fan-shaped body merges head direction with goal direction to produce motor commands. In this diagram, M.ip represented as if it resembles the fan-shaped body.
If the M.ip functionality is similar to the fan-shaped body, it’s highly likely to be convergent evolution, not homology because amphioxus lacks any similar structure.
Dark search
When zebrafish are plunged into darkness, they initiate a search that continues for about five minutes. The darkness behavior increases speed and straight behavior [Horstick et al 2017]. In other words, phototaxis is not just gradient behavior but also has steady-state darkness behavior. Because zebrafish require light to hunt, darkness in itself is is an area to avoid.
The essay is purely gradient based and has no speed changes. Photokinesis is moving faster in darkness and slower in light, which will bias the time spent in the light area.
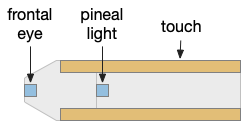
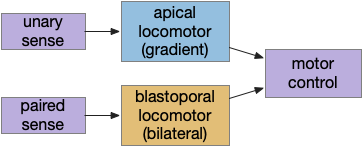
Although the previous essays have focused on bilateral locomotion in the style of Braitenberg machines, the chimaera brain hypothesis [Tosches and Adrendt 2013] suggests a distinct apical form of locomotion. The chimaera brain hypothesis suggests that bilaterian brains are the merger of an apical nervous system from the ancestral zooplankton larva state and a blastoporal (bilateral) nervous system from paired muscles along the spinal cord. The apical area contains unpaired light and chemical sensors and the blastoporal area contains bilateral, topographic somatic sense like touch. Apical navigation require a temporal gradient, calculated by sequential sampling because the apical senses are non-directional.
Apical unpaired light sensors and bilateral paired touch sensors in the chimaera brain.
The essays’ simulation scenario is a temporal phototaxis based on the real-time place preference (RTPP) experiments of [Chen et al 2014], where a zebrafish stayed inside a virtual light circle, avoiding surrounding dark area. Temporal phototaxis is gradient-based locomotion, heading toward light and away from darkness by comparing light samples at different times.
Chimaera locomotor
The vertebrate paired eye and paired olfaction are late vertebrate developments. The pre-vertebrate animal amphioxus has only a single frontal eye. Since pre-paired sense animals needed to navigate toward opportunities and away from threats, it’s conceivable that apical random-walk navigation developed before visual navigation.
Dual navigation system based on both temporal gradient-based random walks and bilateral spatial gradient navigation.
Apical gradient
The apical area contains undirected light and chemical sensors. The apical area is based on the zooplankton larval state as shown below, while the bilateral area is based on bilateral worm-like adults structured like the spinal cord of paired muscles and neurons.
Apical zooplankton larva. Note the single sensor on top.
Apical navigation requires following a temporal gradient, calculated by sequential sampling. While bilateral areas can compare left and right senses to calculate a spatial gradient, the single apical sense is restricted to a temporal gradient.
Bacteria tumble and run
Even simple bacteria can follow gradients using a directed random walk strategy called tumble and run [Segall et al 1986]. The bacteria’s flagella have two modes: tumble, turning without moving, and run, moving forward without turning. By alternating tumble with run, the bacteria can search with a random walk. By extending the run phase when the gradient improves, the bacteria can move toward the target.
Importantly, a temporal gradient calculation needs some sort of memory, accumulator or integrator to compare the current value to recent values. In bacteria, tis accumulator is an internal chemical quantity.
Different turning behavior depending on the gradient. Sharp turns moving into darkness and straight movement into light.
Apical and bilateral sensors
Amphioxus is a pre-vertebrate chordate that’s studied to understand vertebrate evolution. Amphioxus does not have a paired eye, instead it has a single frontal eye that amphioxus uses to orient vertically, and also a pineal-like photoreceptor [Lacalli 2020].
The pineal region is near the vertebrate habenula. Amphioxus does not have a habenula, but it does have a nearby motor control neuron, LPN3, with similar genetic markers [Bozzo et al 2023]. Modern vertebrate medial habenula receives undirected light input from the retina, but it seems plausible that an early habenula used the pineal photosensor because both are part of the same epithalamus complex, and only later connected to the newly-paired retina when it developed.
Multiple apical regions
Before diving into the vertebrate areas for apical locomotion, I need to explain why widespread areas can all be apical, including midbrain and hindbrain areas. Vertebrates had two rounds of whole genome duplication [Dehal and Moore 2005], which gives an easy evolutionary opportunity for four apical areas from the genome duplication, in addition to other possible duplications. The xenobot experiments [Blackiston et al 2023] shows that biology can mix multiple copies like the split apical area into a coherent animal: development can be flexible.
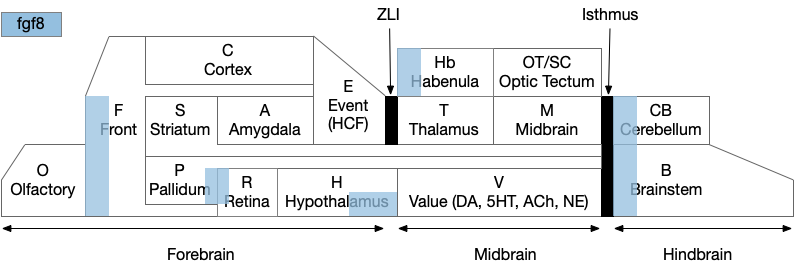
Functional vertebrate brain model showing apical areas as marked by fgf8 development transcription factor.
The diagram above is a functional representation of the vertebrate brain with possible apical areas highlighted in blue. Fgf8 is a development growth factor associated with the apical area [Marlow et al 2014]. The four (or five) possible apical area are as follows:
Prefrontal cortex and olfactory bulb.
The caudal isthmus area (r1) at the midbrain-hindbrain boundary, including cerebellum (CB), interpeduncular nucleus (M.ip), midbrain locomotor (MLR, M.ppt, M.ldt), head direction (B.dtg), parabrachial (B.pb), and part of the substantia nigra (Snr).
Habenula (Hb) and pre-thalamic eminence area (P.em) near ZLI. Also, between the septum-diagonal band (P.msdb) and preoptic area (Poa) near the optic (retina) region (R).
The mammilary and supramammilary area of the hypothalamus (H.mb and H.sum).
I’ve listed four regions instead of the five blue areas because the Hb-P.em-P.msdb area are physical closer than the diagram suggests, are split more by the alar/basal division than distance, and is complicated by distortions from the paired optic region.
This essay uses functions from the r1 isthmus area (M.ip and MLR.α / M.ldt), and from the habenula / retinal area (Hb.m, P.em, pineal, and retina). The logic behind their connectivity is a function split-and-pull like taffy or continental drift from a single pre-duplication area, for example, the isthmus apical area duplicating from an original pre-hypothalamus / retinal apical area.
As a note, the supramammilary area (H.sum) is highly connected with the area in this essay, but I’m postponing exploring its functionality for now.
Vertebrate apical and bilateral locomotor
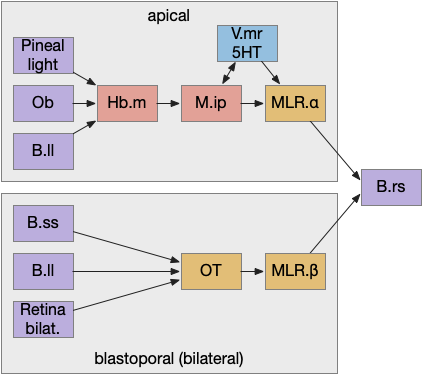
Previously the essays used the bilateral locomotor path, going through the Vta (posterior tuberculum), tectum (OT), and midbrain locomotive region (MLR). The apical path runs through the medial habenula (Hb.m) and the interpeduncular nucleus (M.ip) before reaching the motor neurons.
Bilateral and apical locomotive paths. B.ll lateral line, B.rs reticulospinal motor neurons, B.ss somatosensory, Hb.m medial habenula, M.ip interpeduncular nucleus, MLR midbrain locomotive region, OT optic tectum, V.mr median raphe, 5HT serotonin.
The lamprey’s Hb.m supports locomotion for light, odor, and the lateral line [Stephenson-Jones et al 2012]. The lateral line is an aquatic sense for water flow, which allows fish to sense nearby objects. Although the exact functional division of phototaxis isn’t known, Hb.m, M.ip and the serotonin raphe nuclei (V.mr – 5HT) are all required [Cheng et al 2016].
For the essay’s simulation, I’m asking the integration and running average to the V.mr and 5HT, but this is something of a guess, because phototaxis integration hasn’t been measured. In the essay’s model, M.ip translates the light data and 5HT average into a gradient and into action.
Phototaxis actions
When zebrafish enter darkness from light, they immediately produce a large turn (O-bend) and start an area restricted search (ARS) [Fernandes et al 2012]. Later turns are smaller [Chen and Engert 2014].
For the essay, phototaxis gradient modifies the standard random walk. When entering darkness, M.ip increases the turn angle. When entering light, M.ip increases forward movement, extending the run.
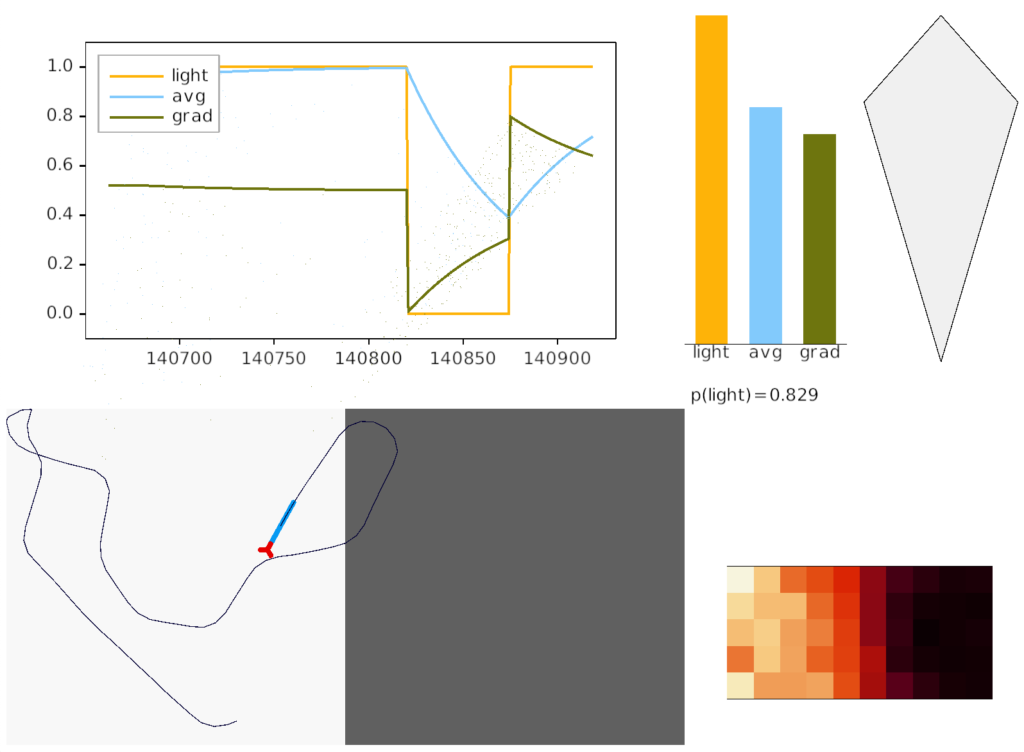
Essay simulation showing the animal returning to light from darkness. The graph shows the gradient change when crossing the darkness boundary.
The above screenshot shows the animal crossing into darkness and returning to light. In the graph, “light” is the current photosensor value, “avg” is the running average measured by serotonin neurons, and “grad” is the different between the two. A gradient drop triggers high angle turns. A gradient rise triggers straight movement.
As the heat map in the right shows, this simple system produces real-time place avoidance (RTPA) of darkness. Since the system has no learning, there’s no conditioned place aversion (CPA).
Prethalamic eminence
The full phototaxis circuit in vertebrates is a bit more complicated because light input does through an intermediate area called the pre-thalamic eminence (P.em), which is between the habenula, hypothalamus and thalamus, and it one of the apical areas. Although P.em is not cortical, it provides neurons necessary for cortical development (Cajal-Retzius neurons for L1 patterning) [Marin-Padilla 2015] and neurons for habenula input, the habenula-projecting pallidum (P.hb) [Stephenson-Jones 2016].
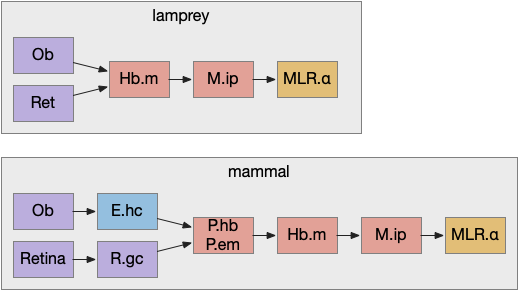
Apical navigation paths, simplified in lamprey and extended in mammals. E.hc hippocampus, Hb.m medial habenula, M.ip interpeduncular nucleus, MLR midbrain locomotive region, Ob olfactory bulb, P.em pre-thalamic eminence, P.hb habenula projecting pallidum, R.gc retina ganglion cells.
Retina input goes through P.em to Hb.m for phototaxis. Interestingly, the main input for Hb.m in mammals is via cells that migrate from P.em and become the posterior septum (P.ps) [Watanabe et al 2018], which receives almost all of its input from the hippocampus (E.hc). If the hippocampus is an odor-processing system, then the olfactory bulb (Ob) to E.hc to Hb.m path is a chemotaxis path matching the retina’s phototaxis path.
Note that the olfactory placed develops from the lens placed and is differentiated by fgf8 [Bailey et al 2006]. So, it’s pleasing that the similar olfactory and hippocampal paths to Hb.m is a are chemotaxis and phototaxis paths split from a common ancestor.
Speculation
Although the lateral and medial habenula are chemically, connectional, and developmentally distinct, their broad similarity is interesting. If the medial habenula supports direct, concrete sensory navigation by gradient descent, perhaps the medial habenula supports more abstract value-based navigation for more abstract goals.
I like the model of motivation where the hypothalamus and midbrain structures like the ventral tegmental area (Vta), periaqueductal gray (M.pag), and parabrachial nucleus (B.pb) form the motivational core, primarily run by neuropeptides signaling, based on old chemical communication. [Damasio and Carvalho 2013] consider this area as an organized map for feelings, like the optic tectum (OT) has a retina-centric map for visual interest.
To avoid getting stuck in philosophical woo, I’m avoiding the question of whether this area is a primary source of feelings, but I like the idea of a semi-organized map at the base of motivation. The parabrachial nucleus (B.pb) is a good place to start, because its neurons encode warnings like pain, visceral summaries, and primitive feeding, including basic taste.
Parabrachial nucleus
B.pb provides a coarse summary of taste, pain, temperature, and visceral feelings like malaise without the details. It can report that something tastes good because it’s sweet or tastes bad because it’s bitter, but can’t experience chocolate. It’s more of an action-focused alarm [Campos et al. 2018] than a sensory experience.
For example, if B.pb detects bitter taste or malaise, it sends a general notice to other areas in the peptide core to stop eating and investigate further. If B.pb tastes sweet, it encourages eating. In addition to senses like taste and warning, B.pb has action control of its own, including reflexive escape actions, breathing and heart rate to the medulla (B.mdd) and B.nts. So, it can serve as a lower-level action hub.
B.pb and neuropeptides
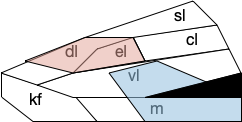
B.pb poses an immediately difficulty for the simulation animal because it’s organized chemically by neuropeptides instead of a simple topological and connectivity map. The following diagram is a broad topographic map of B.pb [Chiang et al. 2019] that illustrates the issue.
Topological map of the parabrachial nucleus.
As shown above, the colored areas do not respect the named boundaries. The blue area represents taste neuron areas and the red area represents general alarm (pain, heat, cold, malaise, etc.) But even those colored areas are an oversimplification because neuron functions are mixed together salt-and-pepper style. [Pauli et al. 2022] found 21 subclusters of B.pb neuron peptide receptors and transmission, each of which may have distinct projection patterns.
This neuropeptide focus isn’t restricted to B.pb. The lateral hypothalamus (H.l), another major node in the feeding circuit, is also organized by neuropeptides, including important ones like orexin (exploring), and MCH, which it sends across the entire brain. Although [Diaz et al. 2023] has broken H.l into 9 areas, these may not be sufficient because of the neuropeptide focus. [Mickelsen et al. 2019] found 15 clusters of glutamate neurons and 15 clusters of GABA neurons. [Guillaumin and Burdakov 2017] and [Burdakov and Karnani 2020] find H.l functional communication through neuropeptides that are invisible to traditional synaptic communication.
Neuropeptide core
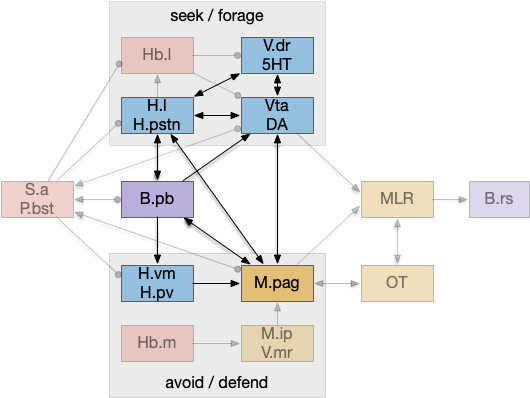
An “isodendritical core” [Ramón-Moliner and Nauta 1966] in the hypothalamus and midbrain is an old idea with a more modern description in [Agnati et al. 2010], which is a good starting point for the essay simulation. The core includes reticular areas of the hypothalamus, B.pb, M.pag, and the Vta (aka posterior tuberculum in zebrafish). “Neuropeptide core” matches my imagination of this area better than the old name. A diagram of the core is below, with the caveat that neuropeptide broadcasting is more important for communication than the diagram’s arrows.
Neuropeptide core in bright colors, associated areas greyed out. B.pb parabrachial nucleus, B.rs reticulospinal motor command, H.l lateral hypothalamus, H.pstn parasubthalamic nucleus, H.pv periventricular nucleus, H.vm ventromedial hypothalamus, Hb.l lateral habenula, Hb.m medial habenula, M.ip interpeduncular nucleus, M.pag periaqueductal, MLR midbrain locomotor region, OT optic tectum, P.bst bed nucleus of the stria terminals, S.a central amygdala, V.dr dorsal raphe (serotonin), V.mr medial raphe, Vta ventral tegmental nucleus (dopamine).
As shown above, the neuropeptide core is highly interconnected. B.pb includes taste and visceral sensation like nausea together with visceral control. H.l includes blood sensors like glucose level, insulin, and fat and protein levels. M.pag includes many innate behaviors including freezing, flight and grooming. Vta controls actions, including seeking and searching.
As the diagram illustrates, the neural connectivity of the inner core is not particularly useful because they’re all entirely interconnected. For simplicity of the essay simulation, I’m using a model where the core neuropeptides are shared in a common neuropeptide soup, or canal, where the neuropeptide identity is more important than the neuron’s specific physical location. For example, treating B.pb as one or two areas instead of the seven areas above.
Cerebrospinal fluid as neuropeptide canal
The periventricular areas like H.pv and M.pag are named for their location around the ventricles, which contains cerebrospinal fluid (CSF). These areas contain neurons that directly sense neurotransmitters and neuropeptides in the CSF itself. The CSF can be a canal for transmitting neuropeptides [Bjorefeldt et al. 2018].
Earlier photo-vertebrate animals may have used a similar canal more extensively. Because of the smaller brain size, diffusion in the canal may have been sufficient for communication without point to point synapses. [Vigh et al. 2004] point out that amphioxus larva, a pre-vertebrate chordate, has much of its com munition in a single neuropile (intertwined dendrites and axons) that’s open to sea water until its neural tube closes as an adult.
Neuropeptides and timing
Neuropeptides act on a much slower timescale than faster neurotransmitters like glutamate and GABA. Glutamate and GABA synapse are a few microseconds and clear rapidly. Neuropeptides can persist tens of seconds to tens of minutes. For an animal’s motivation, like fleeing a predator, the longer timescale is more appropriate, because the animal shouldn’t stop fleeing if it loses sight of the predator for ten milliseconds or even a second or two. Similarly, foraging for food is a longer task measured in many minutes or hours, not milliseconds. The longer chemical timing of the peptides is more suited to motivational timing than the fast reactive transmitters.
Peptide circuits
I’ve sketched out some possible neuropeptide circuits for feeding are portrayed in the diagram below, organized by behavior.
Sketch of some of the neuropeptide circuits related to feeding.
The first diagram shows dopamine as a primary seeking neurotransmitter [Alcaro et al. 2007]. When the animal finds target by odor in the simulation, dopamine tells the Vta to connect the olfactory bulb (Ob) to the motor locomotive region (MLR), aiming the animal to the food scent.
The second shows orexin as a general food exploration signal. In contrast with the target-focused seeking, exploration is a random search.
The third is part of the eating circuit, where CGRP (an alarm neuropeptide) tonically inhibits eating, until AgRP (a hunger neuropeptide) disinhibits it [Essner et al. 2017].
Chiang, M. C., Bowen, A., Schier, L. A., Tupone, D., Uddin, O., & Heinricher, M. M. (2019). Parabrachial Complex: A Hub for Pain and Aversion. The Journal of neuroscience : the official journal of the Society for Neuroscience, 39(42), 8225-8230.
The essay 22 simulation explored a striatum model where the two decision paths competed: odor seeking vs random exploration, using dopamine to bias between exploration and seeking. This model resembled striatum theories like [Bariselli et al. 2020] that consider the stratum’s direct and indirect paths as competing between approach and avoidant actions.
Issues in essay 22 include both neuroscience divergence and simulation problems. Although the simulation is a loose functional model, that laxity isn’t infinite and it may have gone too far from the neuroscience.
Adenosine and perseveration
Seeking and foraging have a perseveration problem: the animal must eventually give up on a failed cue, or it will remain stuck forever. The give-up circuit in essay 22 uses the lateral habenula (Hb.l) to integrate search time until it reaches a threshold to give up. An alternative circuit in the stratum itself involves the indirect path (S.d2), the D2 dopamine receptor and adenosine, with a behaviorally relevant time scale.
When fast neurotransmitters are on the order of 10 milliseconds, creating a timeout on the order of a few minutes is a challenge. Two possible solutions in that timescale are long term potentiation (LTP) where “long” means about 20 minutes, and astrocyte calcium accumulation, which is also about 10 to 20 minutes.
Adenosine receptors (A2r) in the striatum indirect path (S.d2) measure broad neural activity from ATP byproducts that accumulate in the intercellular space. Over 10 minutes those A2r can produce internal calcium ion (Ca) in the astrocytes or via LTP to enhance the indirect path. Enhancing the indirect path (exploration), eventually causes a switch from the direct path (seeking) to exploration, essentially giving-up on the seeking.
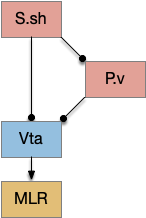
Ventral striatum
Although the essay models the dorsal striatum (S.d), the ventral striatum (S.v aka nucleus accumbens) is more associated with exploration and food seeking. In particularly, the olfactory path for food seeking goes through S.v, while midbrain motor actions use S.d. In salamanders, the striatum only processes midbrain (“collo-“) thalamic inputs, while olfactory and direct senses (“lemno-“) go to the cortex [Butler 2008]. Assuming the salamander path is more primitive, the essay’s use of S.d in the model is a likely mistake.
But S.v raises a new issue because S.v doesn’t use the subthalamus (H.stn) [Humphries and Prescott 2009]. Although, that model only applies to the S.v shell (S.sh) not the S.v core (S.core).
In the above diagram of a striatum shell circuit, an odor-seek path is possible through the ventral tegmental area (Vta) but there is no space for an alternate explore path.
Low dopamine and perseveration
[Rutledge et al. 2009] investigates dopamine in the context of Parkinson’s disease (PD), which exhibits perseveration as a symptom. In contrast to the essay, PD is a low dopamine condition, and adding dopamine resolves the perseveration. But that resolve is the opposite of essay 22’s dopamine model, where low dopamine resolved perseveration.
Now, it’s possible that give-up perseveration and Parkinson’s perseveration are two different symptoms, or it’s possible that the complete absence of dopamine differs from low tonic dopamine, but in either case, the essay 22 model is too simple to explain the striatum’s dopamine use.
Dopamine burst vs tonic
Dopamine in the striatum has two modes: burst and tonic. Essay 22 uses a tonic dopamine, not phasic. The striatum uses phasic dopamine to switch attention to orient to a new salient stimulus. The phasic dopamine circuit is more complicated than the tonic system because it requires coordination with acetylcholine (ACh) from the midbrain laterodorsal tegmentum (V.ldt) and pedunculopontine (V.ppt) nuclei.
A question for the essays is whether that phasic burst is primitive to the striatum, or a later addition, possibly adding an interrupt for orientation to an earlier non-interruptible striatum.
Explore semantics
The word “explore” is used differently by behavioral ecology and in reinforcement learning, despite both using foraging-like tasks. These essays have been using explore in the behavioral ecology meaning, which may cause confusion on the reinforcement learning sense. The different centers on a fixed strategy (policy) compared with changing strategies.
In behavioral ecology, foraging is literal foraging, animals browsing or hunting in a place and moving on (giving up) if the place doesn’t have food [Owen-Smith et al. 2010]. “Exploring” is moving on from an unproductive place, but the policy (strategy) remains constant because moving on is part of the strategy. The policy for when to stay and when to go [Headon et al. 1982] often follows the marginal value theorem [Charnov 1976], which specifies when the animal should move on.
In contract, reinforcement learning (RL) uses “explore” to mean changing the policy (strategy). For example, in a two-armed bandit situation (two slot machines), the RL policy is either using machine A or using machine B, or a fixed probabilistic ratio, not a timeout and give-up policy. In that context, exploring means changing the policy not merely switching machines.
[Kacelnick et al. 2011] points out that the two-choice economic model doesn’t match vertebrate animal behavior, because vertebrates use an accept-reject decision [Cisek and Hayden 2022]. So, while the two-armed bandit may be useful in economics, it’s not a natural decision model for vertebrates.
Avoidance (nicotinic receptors in M.ip)
The simulation uncovered a foraging problem, where the animal remained around an odor patch it had given up on, because the give-up strategy reverts to random search. Instead, the animal should leave the current place and only resume search when its far away.
Path of simulated animal after giving up on a food odor.
In the diagram above, the animal remains near the abandoned food odor. The tight circles are the earlier seek before giving up, and the random path afterwards is the continued search. A better strategy would leave the green odor plume and explore other areas of the space.
As a possible circuit, the habenula (Hb.m) projects to the interpeduncular nucleus (M.ip) uses both glutamate and ACh as neurotransmitters, where ACh amplifies neural output. For low signals without ACh, the animal approaches the object, but high signals with ACh switch approach to avoidance. This avoidance switching is managed by the nicotine receptor (each) which is studied for nicotine addiction [Lee et al. 2019].
An interesting future essay might explore using nicotinic aversion to improve foraging by leaving an abandoned odor plume.